
Dominando las expresiones regulares: El arte de buscar y validar patrones (I)
Publicado por Cristóbal Martínez el
Si has llegado hasta aquí es porque estás buscando aprender a usar y sacar el máximo partido de las expresiones regulares, o estás interesado en este tipo de expresiones, y quieres ampliar o refrescar tus conocimientos.
- ¿Alguna vez has querido encontrar un patrón en un texto? ¿O validar que un dato cumple con un formato específico?
- ¿Has intentado encontrar una información específica en un fichero, pero no has encontrado lo que buscabas?
- ¿Quieres aprender a leer o escribir ese tipo de expresiones ^(?:3[01]|[12][0-9]|0?[1-9])([\-\/\.])(?:0?[1-9]|1[1-2])\1\d{4}$?
- ¿Has intentado validar un dato, pero no encontrabas la manera?
- O ¿quieres aprender un nuevo lenguaje poderoso que te permita controlar el texto?

Si has respondido sí a alguna de estas preguntas, entonces este artículo es para ti. Vamos a descubrir el poder de las expresiones regulares, !Empezamos!
Veremos muchas características acerca de las expresiones regulares, el contenido es bastante extenso, incluyo muchas imágenes y ejemplos, así que para que no te aburras leyendo voy a dividirlo en dos post, en este veremos los conceptos básicos y en el siguiente algunos conceptos menos básicos (no me gusta llamarlo avanzados).
Por supuesto, eres libre de moverte por el contenido hasta la parte que más te interese, aunque te recomiendo verlo entero sobre todo si estás empezando. Puedes ir a la sección de conceptos básicos para empezar directamente con las expresiones regulares o pasar por la sección de introducción, de cualquier forma, te recomiendo que eches un vistazo al apartado de nomenclatura donde se explica como leer los diferentes ejemplos y gráficos que hay a lo largo del post.
El índice hará más sencilla la navegación por el documento y puedes volver a él desde cualquier sección.
Indice de contenidos
- Introducción
- Conceptos básicos
- Para ir cerrando
Introducción
Arrancaremos con los conceptos más básicos, para que el artículo pueda ser seguido, aunque todavía no sepas nada en absoluto sobre las expresiones regulares, al final de cada una de las secciones hay un resumen de lo visto. Al terminar de leer el post habremos visto los suficientes conceptos como para que con un poco de práctica te puedas enfrentar a expresiones de un cierto grado de complejidad. Vamos a ver entre otras cosas:
- Características básicas de las expresiones regulares:
- Meta-caracteres \d, \s, \w...
- Cuantificadores +, *.?, {n,m}
- Grupos y grupos con nombre (...)
- Rangos [...]
- Y Características más avanzadas como:
- Grupos de captura (...)
- Backreferences
- Aserciones lookahead/lookbehind (?= ) (?<= )
- Modificadores (?m), (?i), (?g)
- Condicionales (condición)?(?(n)<if>|<else>)
Aclaraciones previas y nomenclatura
No está de más antes de empezar a ver el contenido y los muchos ejemplos que hay a lo largo del post hacer unas puntualizaciones. El artículo va dirigido tanto a personas que están aproximándose a las expresiones regulares, como a aquellas personas que intentan profundizar en el tema, usaré a lo largo de esta entrada un vocabulario más coloquial y menos técnico para hacerlo lo más accesible posible.
Encontrarás multitud de imágenes para intentar explicar o aclarar conceptos, para interpretarlas correctamente hay que saber que las diferentes coincidencias se muestran resaltadas dentro de un recuadro en tono de azul, todos los ejemplos han sido ejecutados en la página https://regexr.com/ donde puedes encontrar soporte para practicar con las expresiones regulares.
- Cada una de las coincidencias estarán dentro de uno de estos recuadros, por lo que diferentes coincidencias están en recuadros diferentes. Es necesario remarcarlo porque a nivel ilustrativo se ve muy bien cuando están todas las coincidencias juntas, pero los editores o lenguajes de programación encuentran las coincidencias, por lo general, de 1 en 1, salvo que le indiques lo contrario.
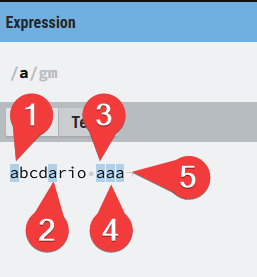
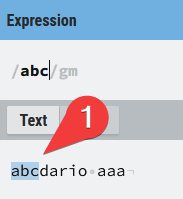
En cada uno de los ejemplos dejaré la expresión regular, y en las que tengan un pequeño grado de complejidad y sea de ayuda se incluirá un gráfico que ayuda a leer que hace cada una de las diferentes opciones que iremos viendo a lo largo del post. Creo que se leen muy bien y espero que te ayuden a clarificar cómo funciona cada una de las expresiones que vamos a ver. Tienen este formato:
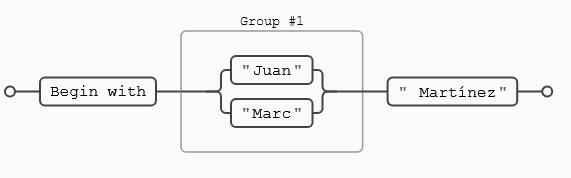
Utilizaré las palabras match, coincidencia como sinónimos. Ahora sí, estamos en disposición de empezar a ver las expresiones regulares.
Un poco de historia (muy breve)
Las expresiones regulares, también conocidas como regex o regexp, son patrones de búsqueda de texto que se utilizan para encontrar, validar o manipular cadenas de caracteres. Su origen se remonta a la década de 1950 con la teoría de autómatas y la lógica formal.
A lo largo de los años, las expresiones regulares se han desarrollado y adoptado en diversos lenguajes de programación y herramientas, convirtiéndose en una poderosa herramienta para el procesamiento de texto y la búsqueda de patrones en cadenas de caracteres. Esta sintaxis fue introducida en el mundo Unix en comandos como awk, sed o el conocido grep, más tarde fue ampliada por POSIX y de nuevo ampliada más tarde por Perl.
Hay varios "sabores" o diferentes motores de expresiones regulares, cada uno de ellos tienes algunas capacidades diferentes al resto, vamos a intentar ver cosas comunes a todas ellas. Os dejo a modo de curiosidad una tabla comparativa.
 Contributors to Wikimedia projects
Contributors to Wikimedia projects
¿Qué es una expresión regular (regexp)?
En general, las expresiones regulares (regex o regexp por la abreviación del inglés regular expression) son patrones de búsqueda definidos en base a un lenguaje, que rastrea coincidencias de ese patrón, o combinación de caracteres, en un texto. Nosotros vamos a definir esos patrones.
Cuando definimos un patrón, o expresión regular, ésta intenta por defecto, que la coincidencia del patrón en el texto objetivo sea lo mayor posible, son lo que se llama expresiones codiciosas o avariciosas. Los motores de expresiones regulares comienzan a analizar el texto de izquierda a derecha y no paran de buscar hasta que encuentran la mayor coincidencia posible que cumple con el patrón que les hemos proporcionado.
En este post nos vamos a dedicar a explicar cómo funcionan las expresiones regulares, y como escribir o leer estos patrones para obtener las coincidencias dentro de un texto. Una vez obtenidas las coincidencias también llamadas ocurrencias o match, a través de código de programación o un simple editor de texto podemos realizar acciones sobre ellas como, por ejemplo, localizar un texto dentro de otro si cumple con el patrón definido, contar el número de coincidencias, sustituirlas por otro texto o eliminarlas, validarlas, darles formato...
Hay que decir que evidentemente no todo vale como expresión regular, hay que conocer las reglas y sintaxis de este "lenguaje", al principio puede asustar por la complejidad de las expresiones obtenidas, pero es más sencillo de lo que parece y sólo hace falta un poco orden a la hora de escribirlas y sobre todo algo de práctica. Estas expresiones están, o pueden estar, compuestas por:
- literales (abcde...)
- números (1,2,3,4,5...)
- meta-caracteres (.*+?[]{}...). ¿por qué meta? Porque estos caracteres tienen un significado especial para la expresión regular, por ejemplo, si un carácter debe aparecer al principio o al final de una línea, si no debe aparecer, si lo hace sólo una o más veces...
Algunas definiciones informales antes de empezar
Literal: cualquier carácter que usamos en una búsqueda.
Meta-carácter: son caracteres especiales que tiene un significado único y no se utilizan como literales en la expresión de búsqueda, en caso de querer encontrar uno de estos caracteres dentro de un texto hay que escaparlos.
Escape o secuencia de escape: es la manera de indicarle a la expresión regular que queremos usar uno de nuestros meta-caracteres como un literal, de manera que carecen del significado especial que entiende la expresión si no llevan el escape. Generalmente consiste en anteponer el signo (\) delante del meta-carácter. Por poner sólo un ejemplo, el signo (?) quiere decir que el carácter o expresión que lo precede es opcional, pero si lo que busco es literalmente el signo de (?) en una frase hay que indicarlo de la siguiente manera (\?). Más adelante iremos viendo muchos más ejemplos.
Expresión de búsqueda: la expresión regular que estamos escribiendo, también llamadas expresiones regulares, regex o regexp.
Cadena o texto objetivo: hace referencia a la cadena de texto que estamos buscando a través de la expresión regular.
Chuleta resumen de expresiones regulares.
Después de hacer muchas expresiones regulares sé de lo complicado que a veces puede ser recordar la sintaxis cuando estás empezando o simplemente cuando llevas un tiempo sin usarlas. Así que para empezar te dejo una de las mejores chuletas o resúmenes que he encontrado y que suelo usar de referencia, así la tienes a mano.
Te recomiendo que te descargues 😉

Fuente: https://cheatography.com/davechild/cheat-sheets/regular-expressions/
Vamos a ver un resumen de los más utilizados y qué es cada uno de los grupos. Para ilustrar los ejemplos usaré una web que en lo personal me gusta bastante para probar todas las expresiones regulares que vamos a ir viendo https://regexr.com/
Caracteres literales
Los caracteres literales conforman la parte más intuitiva de las expresiones regulares. Lo que hacen es buscar, literalmente, un carácter o un conjunto de ellos en el texto objetivo. Es decir, con este tipo de patrones se busca una coincidencia exacta, el mismo o los mismos caracteres y en el mismo orden en que lo hemos especificado. Este tipo de patrones es sensible a mayúsculas y minúsculas, salvo que se esté usando el modificador /i (del inglés insensitive) que veremos en un punto posterior.
Es decir, si buscamos el patrón (abc), busca esta secuencia de letras, y en ese orden exacto. Por ejemplo:
abc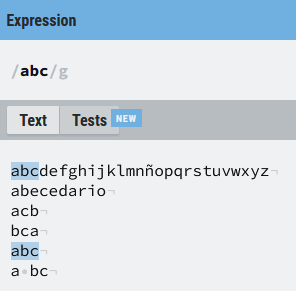
Este patrón dará una coincidencia siempre que encuentre estas tres letras de manera consecutiva, no habrá coincidencia si hay algún carácter o espacio no indicado en la expresión regular, o se encuentran en un orden distinto.
Siguiendo la misma línea la expresión (lo) busca todas las ocurrencias de este texto, independientemente de si es una palabra completa o parte de otra, la secuencia está al principio de una palabra, en el medio o final. Exactamente busca una (l) minúscula, seguido de una (o) minúscula:
lo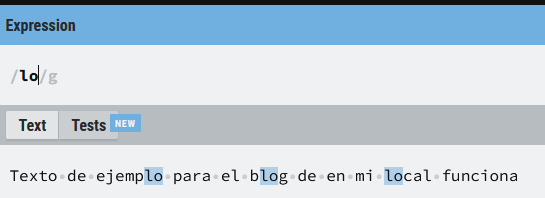
Para terminar con los literales, la secuencia (para) busca todas las ocurrencias de esta secuencia dentro del texto objetivo. Lo que busca es una (p), seguida de una (a), seguida de una (r) y finalmente una (a), todas minúsculas, una a continuación de la otra y sin espacios ni otras letras o signos entre ellas. Lo vemos en un ejemplo con un texto que ayuda a terminar de entender el funcionamiento de este tipo de expresiones.
para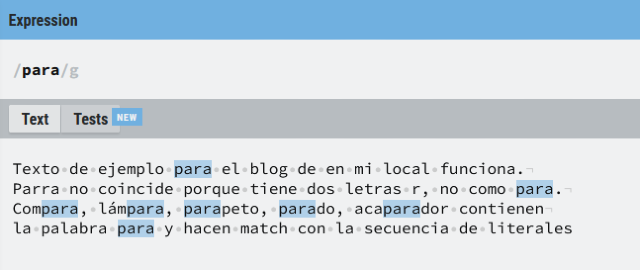
Como puedes intuir este tipo de patrones son los más simples, aunque útiles, no son excesivamente potentes, pero combinados con el resto de las opciones que nos ofrecen las expresiones regulares si pueden llegar a serlo.
Carácter de escape (\)
A lo largo del post vamos a ir viendo diferentes meta-caracteres, que no son más que símbolos (caracteres) que tienen un significado especial dentro de las expresiones regulares, los vamos a ir presentando uno a uno en las siguientes secciones, los más importantes son:
- (
{}) Llaves para grupos - (
[]) Corchetes para clases de caracteres - (
()/\) Paréntesis y barras - (
+ * ?) Signo de más, asterisco e interrogante (cuantificadores) - (
. ^ $ |) Otros símbolos punto, circunflejo, dólar, barra vertical...
Una vez que conocemos los meta-caracteres puede surgir la pregunta de ¿qué pasa si lo que necesito es que mi expresión busque uno de estos caracteres literalmente en el texto objetivo, obviando el significado especial? Pues que para indicarle a la expresión regular que el carácter buscado es literal y que debe prescindir del significado especial, se debe anteponer una (ocurrencias).
¿Es la única función de (\) despojar del significado especial a los meta-caracteres? No, como vamos a ver en las secciones siguientes, algunos caracteres "normales" como la (b), la (n), la (w)... se convierten en meta-caracteres cuando se les antepone un carácter de escape, con lo que adquieren un significado especial para el patrón que estamos construyendo.
De momento, nos interesa el concepto:
- Si la (
\) va delante de un carácter con significado especial, se lo quita. - Si la (
\) va delante de un carácter sin significado especial, se lo da.
Vamos a ver muchos ejemplos a lo largo del post y veremos el significado de todos los meta-caracteres y que caracteres "normales" se convierten en meta-caracteres cuando se les antepone (\). Vamos con un ejemplo sencillo, los paréntesis. Si los quiero buscar literalmente dentro de un texto, necesito escaparlos:
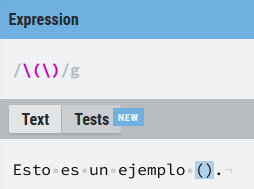
Lo mismo sucede con el resto de meta-caracteres.
Algunos caracteres adquieren un significado especial si se les antepone un carácter de escape. En el ejemplo siguiente el patrón no busca una (b) sino lo que denominamos ancla, que es justo lo que vamos a ver en la siguiente sección.
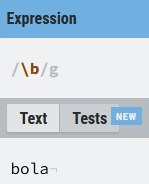
Como puedes ver en la imagen anterior la (b) de bola, no está marcada con el fondo azul, no hay coincidencia, porque el patrón no está buscando el literal (b), sino que adquiere otro significado para la expresión.
Haré incisos a lo largo del post para recordar el concepto de caracteres de escape.
Anclas
Ya hemos visto que puedo buscar una secuencia de letras o números de manera literal en un texto objetivo. Ahora bien, ¿qué pasa si lo que quiero es buscar una secuencia que esté al principio o al final de un texto o línea? Con ese fin podemos usar las anclas.
Las anclas en el contexto de las expresiones regulares son marcadores que se utilizan para delimitar posiciones específicas dentro de un texto. Estas posiciones pueden ser el inicio o el final de una línea, palabra o cadena de caracteres. Las anclas no coinciden con ningún carácter en el texto, pero indican la posición relativa donde debe ocurrir un determinado patrón de búsqueda. Es decir, van a buscar una coincidencia cerca de una posición, inicio o final de palabra, línea o texto.
En primer lugar, vamos a ver qué ocurre si busco un literal que se repite varias veces a lo largo de un texto sin utilizar ningún ancla y después podemos ver las diferencias. Si sólo indicamos el literal habrá una coincidencia por cada vez que se repita la secuencia dentro del texto objetivo, lo vamos a ver más claro con un ejemplo:
texto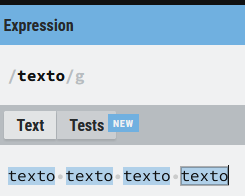
Como ves la expresión regular encuentra la secuencia 4 veces tal y como habíamos visto hasta ahora, pero nos interesa que la coincidencia se produzca sólo si la secuencia está al principio o al final de una línea o texto, para ello vamos a empezar a usar las anclas:
Hay dos tipos principales de anclas:
- Ancla de inicio (
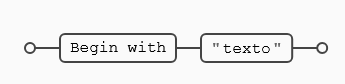
^): Se utiliza para indicar que el patrón de búsqueda debe coincidir solo al comienzo de una línea, cadena o palabra. Por ejemplo, la expresión regular (^Hola) coincidirá con la palabra "Hola" solo si está al principio de una línea. - Ancla de final (
$): Indica que el patrón de búsqueda debe coincidir solo al final de una línea, cadena o palabra. Por ejemplo, la expresión regular (mundo$) coincidirá con la palabra "mundo" solo si está al final de una línea.
Vamos a modificar el ejemplo anterior incluyendo estos meta-caracteres (las anclas), de manera que podemos conseguir que la coincidencia se produzca en el texto anterior sólo con la primara ocurrencia en el caso de usar (^) :
^texto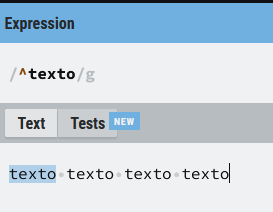
Como podemos apreciar en la imagen anterior la coincidencia se produce sólo con la primera palabra, puesto que el resto no cumplen la condición de estar al principio de la línea tal y como indica (^)
De la misma manera podemos hacer que coincida una secuencia sólo con la parte final de un texto usando el meta-carácter ($).
texto$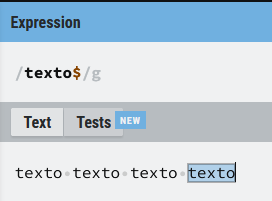
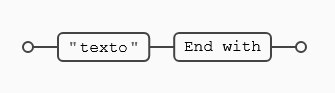
Una posibilidad es indicarle a la una expresión de algo como (^texto$) , lo que le indica a la expresión tanto el inicio como el final del texto o línea, por tanto en este caso buscarán sólo líneas que sólo contengan el contenido entre los meta-caracteres (^) y ($), en el caso del ejemplo la expresión (texto) ya que viene delimitado por las anclas de inicio y final sin posibilidad de que la línea incluya nada más para que se produzca la coincidencia, en la imagen siguiente se ve más claro.
^texto$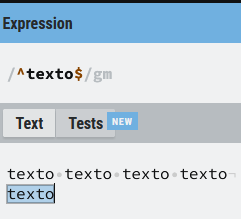
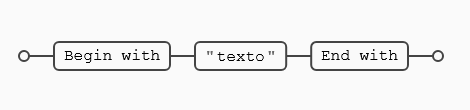
La primera línea no hace match con la expresión porque lo que está buscando es inicio de línea, el literal texto y el final de línea, cualquier otra cosa no coincide con lo que estamos buscando mediante esta expresión regular. En el caso de la segunda línea si se produce la coincidencia con el patrón indicado.
Vamos a ver algunos casos en los que puede resultar útil este tipo de anclas, las pongo a sabiendas de que no hemos visto alguno de los conceptos que se usan en las siguientes expresiones, pero si conoces algo de expresiones regulares o en una segunda lectura seguro que resultan útiles:
- Líneas que empiecen por mayúscula y tienen cualquier contenido (
^[A-Z].*). - Líneas que no empiecen por mayúscula y sigan con cualquier contenido (
^[^A-Z].*). - Líneas que tienes más de 100 caracteres (
^.{100,}$) - Líneas de contenido textual (
^Busco exactamente esto y sólo esto$) - Líneas que contienes sólo números (
^\d+$) - Líneas que empiezan con (
^Inicio) - Líneas que terminan con (
Final$)
Con un poco de práctica y combinando con el resto de las posibilidades que nos ofrecen las expresiones regulares, nos brindan opciones muy interesantes.
Además de las dos anclas que acabamos de ver, existen otras anclas útiles:
- (
\b) hace match al principio y final de palabra. - (
\B) hace match en el resto de las posiciones del texto objetivo que no son ni principio ni final de palabra.
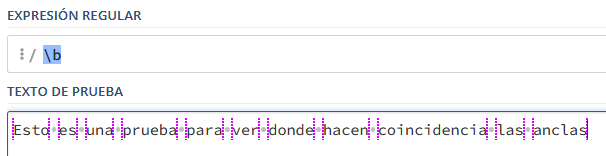
Antes de empezar a ver (\b) es más útil ver de manera gráfica dónde hará match este tipo de ancla, creo que aclara bastante bien el concepto, cada una de las rayas de color rosa en vertical es un punto donde se puede usar un ancla de tipo (\b), al inicio y final de palabra:
La siguiente expresión buscará al inicio de las todas las palabras del texto objetivo la secuencia (en). Sólo habrá coincidencia el inicio de palabra, puesto que el ancla va seguida de literales y eso descarta el final de palabra.
\ben
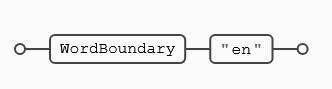
Como vemos en la imagen anterior el ancla está al principio de palabra, por lo tanto la secuencia de letras (en) no hace coincidencia ni es pasen, ni en pende, por no estar ubicadas al inicio de una palabra.
De forma similar la siguiente expresión busca palabras que empiecen por (an):
\ban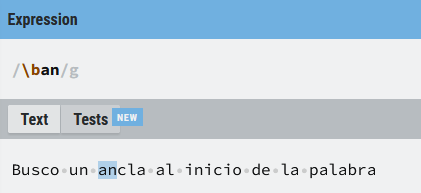
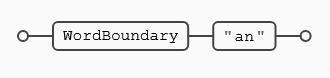
Aprovecho para recalcar que la expresión (\ban) no busca una (b) una (a) y una (n), como si se tratara de un literal, (\b) es un ancla y tiene significado por sí misma que la expresión reconoce y tiene significado propio. No es una (b) escapada, puesto que la (b) no es un meta-carácter, en este caso lo que hace que tenga un significado especial, es precisamente la presencia de la (\) Por tanto, para la expresión regular (\b) hace referencia a cualquier inicio o final de palabra seguida de los caracteres (an).
El siguiente ejemplo es un ancla en palabras que terminen con (o), seguidas de un espacio y de la secuencia de letras (ca). Sabemos que es un final de palabra porque a la izquierda del ancla hay texto, lo que descarta que sea un inicio de palabra:
o\b ca

En el ejemplo anterior busco una (o) al final de una palabra seguido de las letras (ca).
\bla), como en lata.Un ancla al final de palabra tiene el formato (
la\b) como en velaPor tanto, si usamos una expresión del tipo (
\bla\b), sólo hará coincidencia con la palabra (la), pero no con palabra, ni vela, ni lata, por poner unos ejemplos.De acuerdo, ya hemos visto que podemos poner un ancla al inicio y final de una palabra, pero ¿y si quiero buscar una secuencia que esté dentro de una palabra? Pues para eso existe el ancla (\B). De nuevo creo que es más clarificador si vemos de manera gráfica los puntos de anclaje que buscará la expresión regular y que despeja todas las posibles dudas acerca de su funcionamiento. Igual que antes hay un posible anclaje en cada una de las líneas verticales de color rosa, si nos fijamos son todas menos los inicios y finales de palabra:
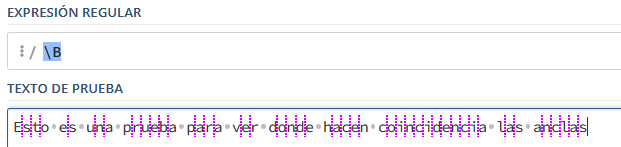
La expresión (\B) es la antítesis de (\b) tiene como objetivo todos los puntos intermedios dentro de una palabra o conjunto de caracteres. En el siguiente ejemplo se busca la secuencia (en) detrás del ancla, por tanto el inicio del la expresión buscada, en este caso (en) debe estar en algún punto dentro de una de las palabras del texto objetivo:

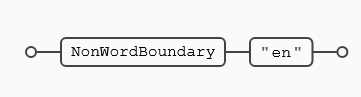
La expresión anterior hace match sólo en el caso de que la secuencia de letras (en) esté dentro de una palabra, ni al principio ni al final de esta.
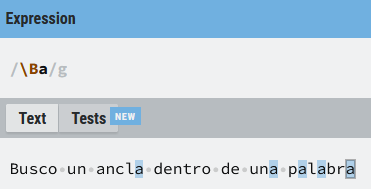
Puede resultar un poco confuso al principio, pero es posible que (\B) haga match con la última o ultimas letras de una palabra, por ejemplo, (\Ba) usará las anclas en (palabra) cuya siguiente letra sea una a, es decir, detrás de la primera (p) entre la (p) y la (a), después de la (l) entre la (l) y la (a) y después de la (r) entre la (r) y la (a).

Si detrás de alguno de estos puntos de anclaje hay una (a) (caso del ejemplo \Ba), habrá una coincidencia, independientemente de la posición en la que se encuentre dentro del texto objetivo. En el ejemplo se da tres veces detrás de la (p), detrás de la (l) y detrás de la (r). Lo que quiero remarcar es que la última (a) de la expresión (palabra) hace coincidencia porque entre (r) y la (a) hay un ancla que cumple la condición, no porque sea final de palabra. En la imagen se ve más claro:
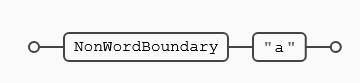
Vamos a ver el ancla (\ba) para tener visualmente las diferencias, sólo hace match con la (a) final por encontrarse al final del texto objetivo, y no con las otras dos letras (a), como si ocurría con el ancla (\B)
Un ejemplo en el que este tipo de anclas puede ser útil. Imagina que quieres buscar la palabra (para) dentro de un texto, si utilizamos las expresiones literales tendríamos algo como esto:
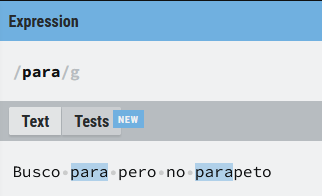
Hemos encontrado la palabra (para) correctamente, pero también hay una coincidencia con (parapeto) y no era nuestra intención. En este caso puede resultar de ayuda el uso de anclas, por ejemplo:
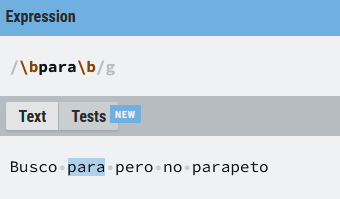

O adelantándome un poco a otras cosas que vamos a contar, me interesa buscar palabras que empiezan por para, como paralelo, pero que no sean la palabra para. Podríamos hacer algo como lo siguiente:
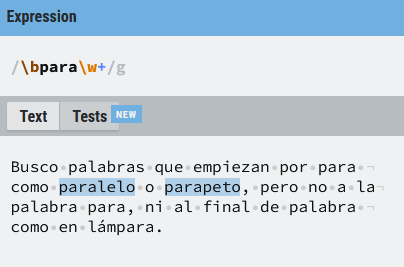

Algunos ejemplos con estas expresiones son:
- Fechas en formato dd-mm-aaaa (
\b\d{2}-d{2}-d{4}\b) - Correos electrónicos (
\b\w+@\w+\.\w+\b) - El número del NIE sin las letras
\B\d{7}\B)
\B\d{7}\B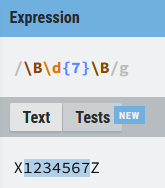
O si me interesara tener el identificador completo podría hacer algo como esto:
[XYZ]\d{7}[A-Z]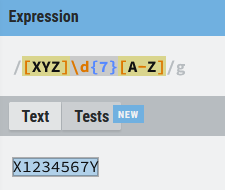
\w+ing$.Clases de caracteres.
Conocidos como clases de caracteres o conjuntos, se representan con unos corchetes ([]). Se usan para indicar a la expresión un conjunto de caracteres, existe la opción de usar un guion dentro para indicar un rango.
Las clases de caracteres son muy útiles porque permiten representar una determinada tipología de caracteres, lo que nos lleva a simplificar las expresiones regulares, al hacerlas más cortas, también más legibles, y por qué no decirlo, nos ahorra algo de trabajo a la hora de escribirlas y eso nos gusta a todos.
En ocasiones es posible que no busquemos un literal concreto, sino que este esté dentro de un conjunto de posibles valores, en estos casos es cuando usamos el - dentro de la clase de caracteres, de manera que la expresión regular busca dentro de un rango. Vamos a verlo con algunos ejemplos.
La expresión ([abc]) valida si una letra del texto objetivo coincide con una de estas tres letras. Es diferente a buscar (abc) que buscaba esa secuencia y en ese orden exacto, con ([abc]) tendremos coincidencia (o match) en caso de que el carácter coincida con (a), con (b) o con (c), y sólo con una de ellas.
En el siguiente ejemplo no uso los rangos, por lo que la expresión lo que busca es la secuencia (abc) dentro del texto objetivo:
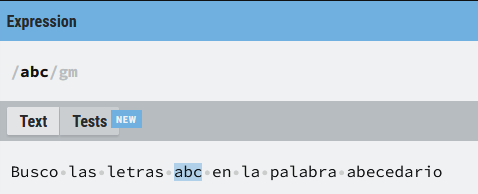
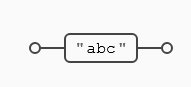
Vamos a ver ahora la diferencia con un rango, simplemente vamos a poner entre ([]) letras que estamos buscando, en este caso (a), (b) o (c) y vemos las diferencias con la expresión literal.
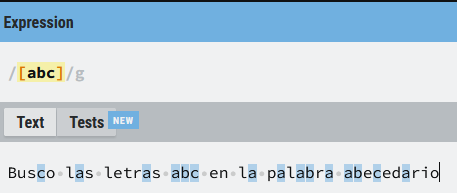
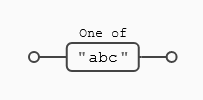
Como podemos observar el resultado ha cambiado mucho con respecto a la expresión anterior, ya no evalúa buscar la secuencia exacta (abc), sino que lo que se valida es que en el texto objetivo cada una (y sólo una) de las letras coincida con (a), o (b) o (c). De hecho si nos fijamos en la secuencia (abc) de la expresión anterior podemos ver que es un todo, sin embargo, en la segunda expresión cada una de las letras es una coincidencia por sí misma.
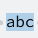
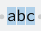
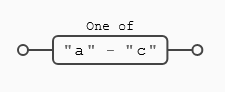
Como hemos dicho los rangos o clases de caracteres todavía tienen alguna característica más que podemos aprovechar a la hora de escribir nuestras expresiones regulares. Este tipo de expresiones permiten buscar por secuencias numéricas o alfabéticas, para ello es suficiente incluir un (-) para delimitar el conjunto de caracteres que estamos buscando. Podemos simplificar abc por (a-c), lo que significa cualquier letra de la (a) a la (c) minúsculas, es decir (a), (b), (c).
En caso de tener (a-e), sería equivalente a (a), (b), (c), (d), (e) con el abecedario inglés, no con las vocales que puede ser un error frecuente al empezar. Vamos a verlo de manera gráfica, dónde el resultado es el mismo que habíamos visto anteriormente, donde ([abc]) es equivalente a ([a-c]):

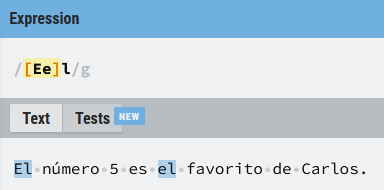
Este tipo de expresiones son útiles en casos como el del siguiente ejemplo, donde queremos buscar la palabra (el) independientemente de su posición en la frase. La expresión ([Ee]l) busca una (E) o una (e) seguidas de una (l), (cuidado que no busca (Él) o (él))
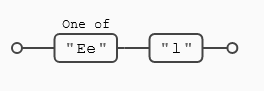
Se usa con mucha frecuencia en expresiones como (médic[oa]), donde habrá coincidencia con las palabras médico y con médica.
Si quieres adelantarte un poco puedes probar esta otra expresión que también admite plurales:
\b[Mm]édic[oa]s?\b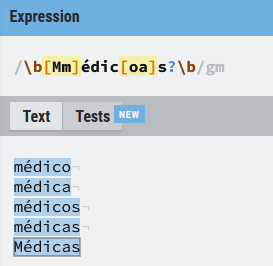
Vamos a buscar palabras que empiecen por (c), (d), (f), (p), (t) o (v) y sigan con las letras (an):
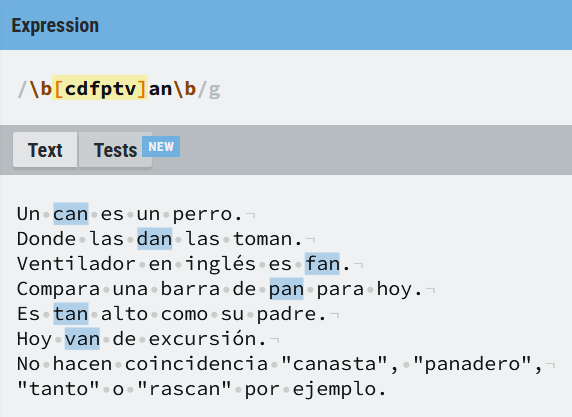
Algunas precauciones para tener en cuenta:
- Los rangos no incluyen:
- las vocales acentuadas
- las letras ñ o ç
- las vocales con diéresis
Lo podemos comprobar en la siguiente imagen:

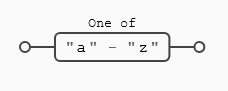
Tal y como habíamos comentado la expresión no coincide ni con las mayúsculas, ni con las vocales acentuadas ni con las letras ñ o ç.
Otros rangos para tener en cuenta:
- (
[a-z]) cualquier letra minúscula (con las salvedades anteriores)- Equivalente a (
[abcdefghijklmnopqrstuvwxyz])
- Equivalente a (
- (
[A-Z]) cualquier letra mayúscula (con las salvedades anteriores)- Equivalente a (
[ABCDEFGHIJKLMNOPQRSTUVWXYZ])
- Equivalente a (
- (
[a-zA-Z]) cualquier letra mayúscula o minúscula (con las salvedades anteriores)- Equivalente a (
[abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ])
- Equivalente a (
- (
[0-9]) cualquier número del 0 al 9- Equivalente a (
[0123456789])
- Equivalente a (
- (
[a-zA-Z1-9]) cualquier letra mayúscula o minúscula, o cualquier número del 0 al 9 (con las salvedades anteriores)- Equivalente a (
[abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789])
- Equivalente a (
Es posible añadir más caracteres a un rango en función de las necesidades que tengamos, por ejemplo ([a-z\-\\]). En este caso vamos a buscar las letras minúsculas de la (a) a la (z) además de los símbolos (-) y (\). Aprovecho para recordar que como son meta-caracteres si queremos hacer una búsqueda literal de ellos hay que escaparlos, es decir, anteponer una (\) (es el símbolo usual de escape en una expresión regular aunque podría ser otro en los diferentes motores de expresiones regulares o lenguajes de programación)
Como ejemplo final, si lo que queremos es buscar un número hexadecimal donde cada uno de los números pueden tomar valores del 0 al 9 y las letras (a), (b), (c), (d), (e) y (f), para un hash o similar, el rango a usar podría ser algo similar a esto ([0-9a-fA-F]), es decir, letras de la (a) a la (f) mayúsculas o minúsculas y los números del 0 al 9, lo que sería el equivalente de ([abcdefABCDEF0123456789]), esta última forma es mucho más engorrosa, y por supuesto, menos recomendada. Por ejemplo el número 255 en hexadecimal sería FF que valida la expresión regular (\b[0-9a-fA-F]+\b)
Como puedes ver las clases de caracteres son de mucha ayuda a la hora de escribir una expresión regular, tanto para escribir una expresión como a la hora de leer una expresión ya existente bien sea nuestra o de algún compañero.
En los ejemplos anteriores hemos usado rangos completos, de la(a) a la (z), del 0 al 9... ni que decir tiene que podemos usar rangos más pequeños y usar varios de manera simultánea en la misma expresión. Por ejemplo esta expresión ([a-et-z3-7]) buscará letras de la (a) a la (e), de la (t) a la (z) y números del 3 al 7. Una imagen como siempre vale más que mil palabras:
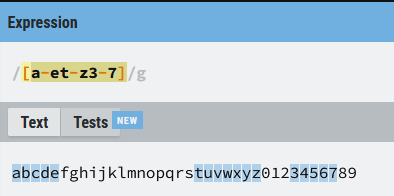
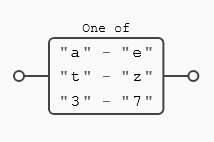
Dejo como ejercicio esta expresión ([0-37-9]), ¿qué coincidencia tiene sobre el texto objetivo 0123456789?
Combinando [] y ^
Ya hemos hablado de las clases de caracteres, y cómo es posible hacer que tengamos una coincidencia con uno de los caracteres encerrados entre corchetes. Como hemos visto los ([]) indican un rango o conjunto de valores válidos para identificar un carácter dentro de una expresión regular, pero ¿qué pasa si lo que quiero es que esos caracteres no aparezcan?
Vamos por partes, hemos visto que el meta-carácter (^) indica que un texto o línea (ver la sección de modificadores o banderas) tiene en su inicio uno o varios caracteres. Pero existe la posibilidad de combinar ([]) y (^), en este caso el significado del meta-carácter cambia. En este caso el meta-carácter (^) indica que la expresión hará coincidencia o match con cualquier cosa que no esté incluida en el rango que está dentro de los ([]) . Vamos a verlo con ejemplos.
La expresión ([a-c]) le indica a la expresión que debe buscar los caracteres (a), (b) o (c). Sin embargo la expresión ([^a-c]), le indica a la expresión que busque cualquier cosa que no sea ni (a) ni (b) ni (c).
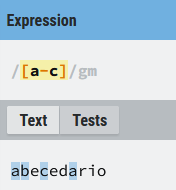
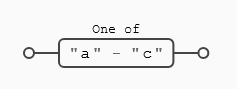
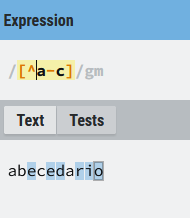

Como has podido ver en el ejemplo anterior las expresiones regulares permiten combinar la negación con el rango ([^a-c]), la expresión equivalente en este caso sería ([^abc]),
Simplificando aún más las clases de caracteres (notación abreviada)
Vamos a ver ahora un tipo de expresiones que nos pueden ayudar a simplificar, todavía más nuestras expresiones regulares, son de uso común por lo que se hace necesario conocerlas para poder leer y escribir nuestras propias expresiones, es lo que podemos denominar métodos abreviados. Recuerda los caracteres de escape, que dotan de un significado especial al patrón de búsqueda:
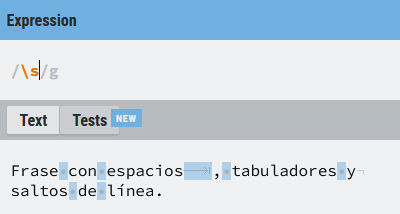
\s
Hace match con cualquier espacio dentro de una expresión regular, de la misma manera hace coincidencia con tabuladores (\t) y saltos de línea en sus diferentes versiones (\n, \r, \n, \r)
\S
Es el inverso de (\s) y hace match con cualquier cosa que no sea un espacio.

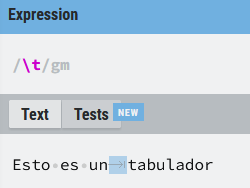
\t
Coincide con el espacio introducido al pulsar una vez la tecla del tabulador de nuestro teclado.
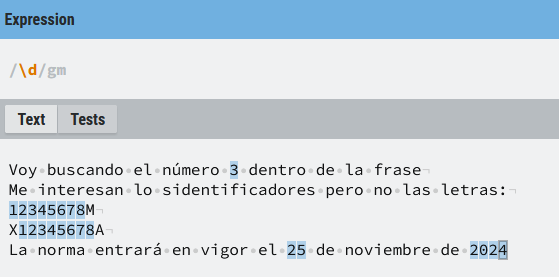
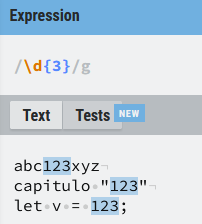
\d
Hace match con cualquier cosa que sea un dígito ([0-9])
Otro ejemplo donde extraer conjuntos de 3 números
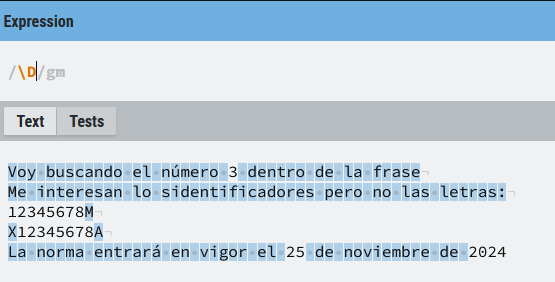
\D
Es el inverso de (\d) y hace cosa con cualquier cosa que no sea un dígito ([^0-9])
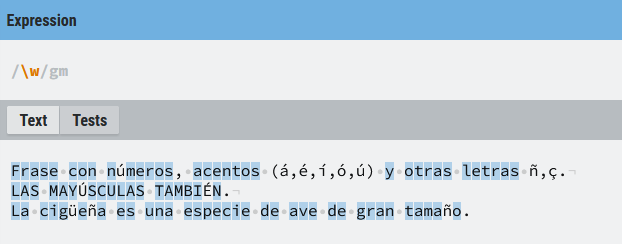
\w
Hace match con cualquier carácter alfanumérico y el (_). Hay que tener precaución porque los caracteres acentuados no están incluidos. Aunque no hemos vistos los rangos esta expresión sería equivalente a esta ([A-Za-z0-9_])
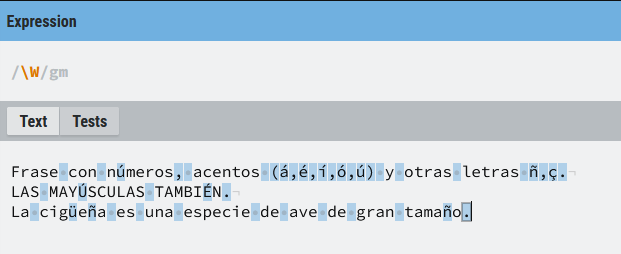
\W
Es el inverso de (\w) y hace match con cualquier cosa que no sea un alfanumérico o un (_), de nuevo la expresión equivalente en rangos sería ([^A-Za-z0-9_])
El punto
El punto, es el ejemplo más simple de meta-carácter, es un comodín, hace match con cualquier cosa, a excepción de los saltos de línea. Con cualquier cosa nos referimos a cualquier carácter, cada punto hace match con un y sólo un carácter, eso sí, puede ser cualquiera.
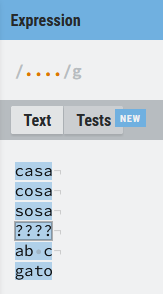
En este punto hay que recordar el carácter de escape:
- Para el motor de búsqueda (
.) significa cualquier carácter - Si busco literalmente un (
.) debo indicarlo con (\.).
Lo vemos en las siguientes dos imágenes para comparar las diferencias, escapando y sin escapar el punto. No es lo mismo la expresión:
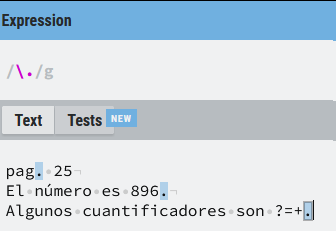
Que la expresión sin escapar:
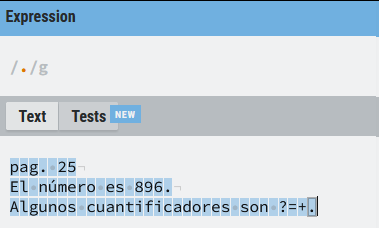
Vamos a verlo de forma gráfica, como se puede apreciar cada uno de los caracteres del texto objetivo es una coincidencia:
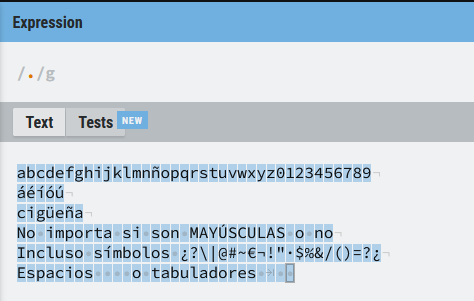
Vamos a ver algunos ejemplos más:
La expresión regular anterior hará coincidencia con cualquier cosa que empiece por (sa) continúe con una letra, espacio, número o símbolo y a continuación tenga una (a). Son resultados válidos por ejemplo sala, saca o saga, pero no salda, porque el punto representa un único carácter dentro de la expresión (al menos hasta que veamos los cuantificadores) .
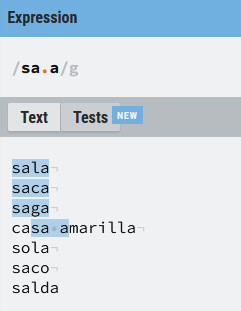

Hay que tener precaución con el . porque puede generar resultados no esperados. En el ejemplo anterior podemos estar buscando palabras del tipo (sala) o (saca), pero hay que tener precaución porque (casa amarilla) también es una coincidencia, y puede que no nos interese como tal, ya que el punto también puede ser un espacio. Como habrás visto no son coincidencia sola por no empezar por (sa) sino por (so), saco porque termina en (o) en lugar de (a) y salda, porque entre (sa) y (a) hay más de un carácter, y el punto representa a un único carácter, por poner sólo algunos ejemplos.
El (.) es uno de los meta-caracteres más comunes, y de los más usados.
Un consejo a la hora de usar el punto (.):
- Como todo hay que usarlo con moderación. Al tratarse de una herramienta muy versátil, a veces nos podemos dejar llevar y usarla en lugar de expresiones más adecuadas. hay que tener cuidado a la hora de usar el (
.) y probar bien nuestras expresiones, no sólo con los casos positivos. - Más adelante veremos cuantificadores y qué significa el (
*), pero en la medida de lo posible hay que evitar expresiones del tipo (.*)
Por ejemplo, queremos validar una fecha en formato dd/mm/aa, y vamos a dejar a elección del cliente el uso del separador entre uno de estos (- o /), por lo que podríamos plantear una expresión de tipo (\d\d.\d\d.\d\d). De momento vamos a dejar para más adelante lo que pasa con las fechas de tipo 42/13/05 y nos vamos a centrar en el uso del punto, por simplificar la expresión resultante, pero lo trataremos en un punto posterior.
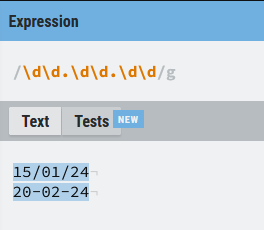

A primera vista parece que nuestra expresión funciona correctamente, pero sólo a primera vista, y es básicamente porque no la hemos probado con casos negativos. Hay que tener cuidado porque nos pueden pasar los separadores mezclados, espacios, letras, espacios o un número de 8 dígitos podrían hacer match con nuestra expresión regular y no es lo que queremos:
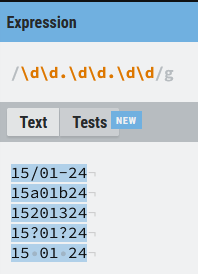

Una expresión de este tipo puede ser un poco mejor que la escrita utilizando el meta-carácter punto: (\d\d[-/]\d\d[-/]\d\d)
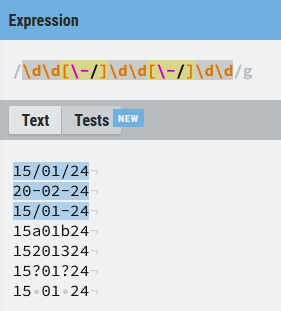

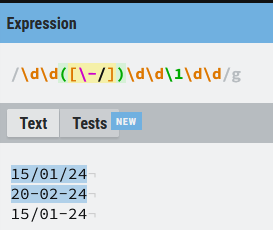
Si te has dado cuenta de que entre los ejemplos, el tercero mezcla los símbolos (-) y (/) y quieres saber cómo hacer que sólo coincidan las expresiones que tienen los dos separadores iguales, tengo que decirte que tienes buena vista y seguro que te gustan las secciones de backreferences y grupos de captura, de todas formas te dejo un adelanto, si no lo entiendes no te preocupes lo vemos un poco más adelante:

Pero espera... si el punto hace match con cualquier carácter a excepción de los saltos de línea, ¿cómo hago match con ellos? Es un buen momento para verlos.
Saltos de línea
- (
\n)Representa un salto de línea en un texto. En la mayoría de los sistemas informáticos, un salto de línea se representa con el carácter de nueva línea (\n). Cuando encuentras (\n) en una expresión regular, indica que estás buscando un lugar donde haya un cambio de línea en el texto. - (
\r) Representa un retorno de carro en un texto. En algunos sistemas informáticos, especialmente en sistemas más antiguos como macOS antes de la versión X, los retornos de carro (\r) se utilizaban para indicar un cambio de línea. Sin embargo, en la mayoría de los sistemas modernos, el carácter de nueva línea (\n) es más común. - (
\r\n) Representa el conjunto de caracteres que indica un cambio de línea en sistemas que usan la secuencia de retorno de carro seguida de una nueva línea. Este es el estándar de cambio de línea en sistemas Windows.
Cuantificadores (repeticiones)
Hay varias opciones a la hora de indicar que un carácter o conjunto de caracteres debe repetirse una o más veces, o una vez, al menos 2 veces...
Vamos a empezar por los básicos los símbolos (*) (+) (?)
- (
*) Indica 0 o más repeticiones del símbolo o elemento que lo precede.- Es muy utilizado aunque como ves es un poco ambiguo, permite que una expresión esté 0 o más veces sin límite. Se suele usar junto con el (
.) para buscar cualquier patrón (.*) indica cualquier cadena alfanumérica.
- Es muy utilizado aunque como ves es un poco ambiguo, permite que una expresión esté 0 o más veces sin límite. Se suele usar junto con el (
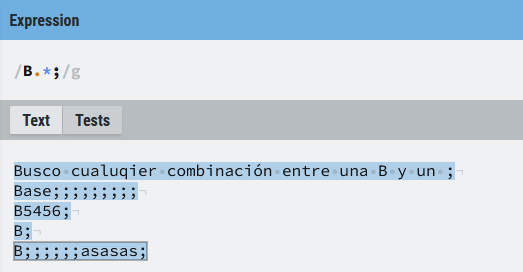
Este tipo de expresiones son muy potentes, porque permiten una gran flexibilidad a la hora de realizar las búsquedas, pero hay que tener especial cuidado, porque también pueden ser especialmente propensas a generar resultados no esperados. Recuerda que este tipo de expresión es ávida, por lo que intentará encontrar la mayor coincidencia posible.
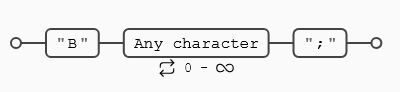
- (
+) Indica 1 o más repeticiones del símbolo o elemento que lo precede.- Vamos a suponer un ejemplo en el que buscamos un identificador, que por simplicidad estará compuesto por un conjunto de dígitos (de momento un número indefinido, pero mayor de 0) y termina con 1 o más letras, la expresión regular podría ser algo como esto:
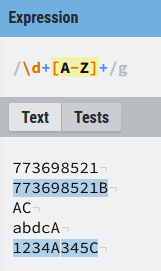
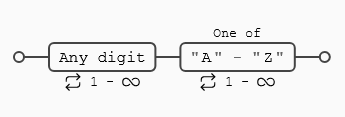
- En la primera línea no hay coincidencia porque el + del final obliga a que al menos la secuencia tenga una letra mayúscula.
- En la tercera línea tercera no hay coincidencia porque no hay número delante de las letras y se necesita al menos 1 (
\d*[A-Z]+) si hubiera hecho match. - En la cuarta línea no hay coincidencia porque las letras son minúsculas
- En la quinta línea podemos ver que hay dos coincidencias (1234A) y (345C)
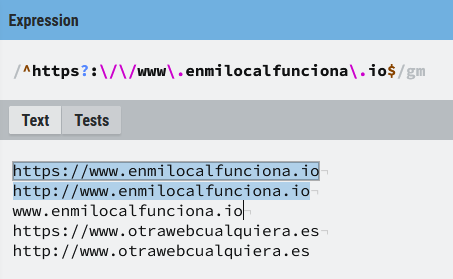
- (
?) Se utiliza para hacer que el elemento que lo precede sea opcional. En otras palabras, indica que el elemento puede aparecer cero o una vez en la cadena que se está evaluando, esto proporciona flexibilidad al buscar patrones en texto, permitiendo que ciertos elementos estén presentes o no en las coincidencias.- Imagina que tienes un texto en que quieres buscar una url, por ejemplo https://www.enmilocalfunciona.io/, pero no sabes si aparecerá como http o como https. Una de las posibles soluciones podría ser el uso del meta-carácter (
?) de modo que la letra (s) sea opcional:
- Imagina que tienes un texto en que quieres buscar una url, por ejemplo https://www.enmilocalfunciona.io/, pero no sabes si aparecerá como http o como https. Una de las posibles soluciones podría ser el uso del meta-carácter (

Es posible utilizar los meta-caracteres no sólo con un único carácter, se puede utilizar con grupos, vamos a buscar por ejemplo un nombre en un texto, pero no tenemos la seguridad de si vendrá o no con el apellido, en cualquier caso quiero recoger la coincidencia, incluyendo el nombre y el apellido si están incluidos en el texto.
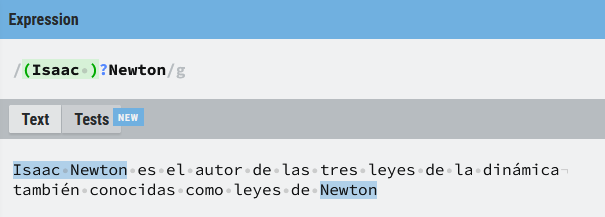
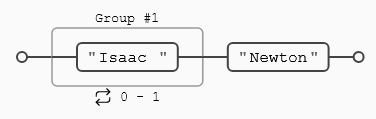
Vamos con un ejemplo en que se combinan, imagina que queremos contar las palabras de un texto, pero que una condición es que palabras como escuela-taller, fisicoquímico, audiolibro... deben contabilizarse como una sola. Una alternativa sería la expresión regular siguiente:


Como siempre en al tratar con expresiones regulares la solución no es única, hay otras válidas como (\w+(-?\w+)), ([a-zA-Z-]*), (\w+-?\w+) ...
Las expresiones anteriores son muy útiles y de uso muy común, aunque hay que decir que no son especialmente precisas, al menos en la parte alta del rango, de 0 a ilimitadas repeticiones, o de 1 a ilimitadas repeticiones. No obstante, también podemos indicar el número exacto de repeticiones de un carácter o grupo de caracteres de una manera más precisa con el uso de llaves ({}).
({n}) La expresión que precede a este cuantificador debe repetirse exactamente n veces.
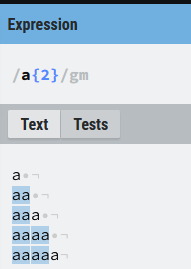
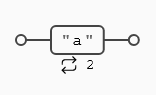
En el ejemplo buscamos 2 vocales a consecutivas, por lo que la expresión encuentra 6 coincidencias.
({n,m}) La expresión que precede a este cuantificador debe repetirse un mínimo de n veces y un máximo de m veces.
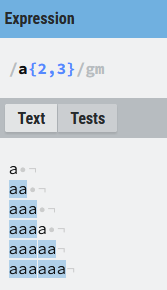
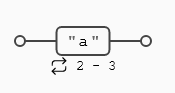
Hay que recordar que las expresiones son avariciosas (o codiciosas), por lo que si pueden tener una coincidencia con el valor más alto no lo harán con el valor más bajo. Por ejemplo, para el caso de 5 vocales aaaaa, empieza por la izquierda y la mayor coincidencia posible es de 3, quedando un grupo de 2, que también hace coincidencia porque es el valor mínimo. Lo mismo ocurre en el caso de cuatro vocales aaaa, si buscara el mayor número de coincidencias posibles encontraría dos grupos de 2, sin embargo como hemos dicho busca la mayor coincidencia posible, que es un grupo de 3, por lo que queda una única vocal que no hace coincidencia al estar por debajo del mínimo, que es este caso era 2.
({n,}) La expresión que precede a este cuantificador debe repetirse un mínimo de n veces sin máximo, por lo que buscará la mayor coincidencia posible a partir de n, 2 en el caso del ejemplo siguiente:
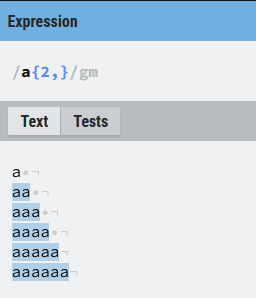
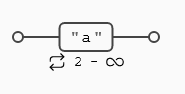
Podemos apreciar en la ilustración anterior la diferencia con el caso ({2,3}), vemos que ahora existe una única coincidencia, a partir de dos vocales, independientemente de su número.
+ para 1 o más repeticiones,
* para 0 o más repeticiones,
? para 0 o 1 repetición (opcional) o
mediante el uso de las diferentes combinaciones de {n,m}
Vamos con un ejemplo para profundizar
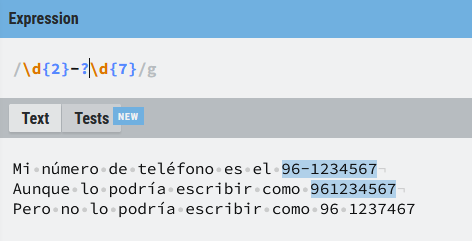
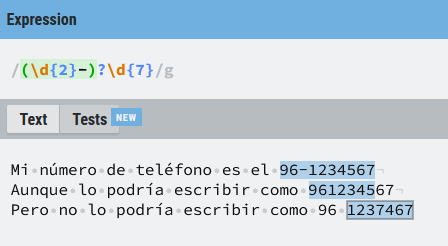
Supongamos que estamos buscando un número de teléfono. De momento, para simplificar buscamos un número de 9 dígitos, en los que los dos números del prefijo pueden ir separados, o no, por un guion (y sólo un guion por simplificar el ejemplo)
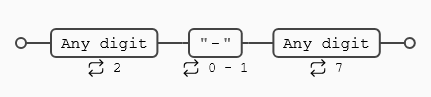
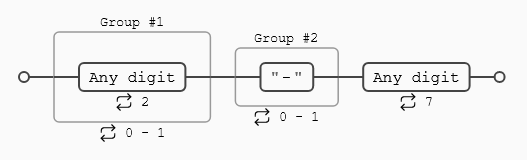
La expresión regular (\d{2}-?\d{7}) busca:
- 2 dígitos
- un (
-) que puede aparecer o no (?) - 7 dígitos adicionales
Antes de pasar al siguiente punto vamos a darle una vuelta a este ejemplo anteriores para intentar profundizar un poco más en el uso de las expresiones regulares.
Hemos propuesto la expresión regular (\d{2}-?\d{7}) en la que el símbolo ? aplica sólo al - que es el que lo precede, pero podríamos querer que el prefijo entero fuera opcional, para ello encerramos la expresión (\d{2}) entre paréntesis. Un poco más adelante veremos los grupos de captura y como hacer que un paréntesis no sea considerado como un grupo de captura.
Si estás empezando con las expresiones regulares quizá lo primero que te venga a la mente es una expresión del tipo ((\d{2}-)?\d{7}) en la que tanto los dos dígitos del prefijo como el guion están englobados en un único paréntesis, pero si lo piensas detenidamente verás que esta expresión tiene un problema, como hemos visto varias veces a lo largo del post las expresiones regulares son ávidas y empiezan a buscar por la izquierda hasta encontrar la mayor coincidencia posible , por tanto:
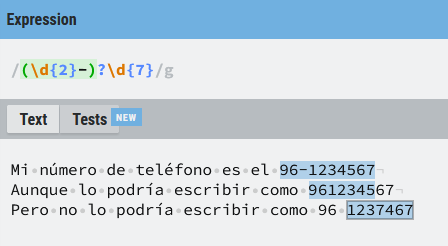
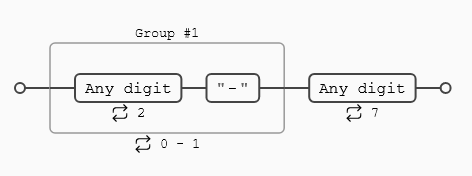
Es posible que coja los 7 primeros caracteres, descartando los dos últimos en el caso de un número con 9 dígitos, porque como no encuentra dos dígitos y un guion, la coincidencia es con 7 dígitos seguidos, y no con el número completo, lo cual está mal.
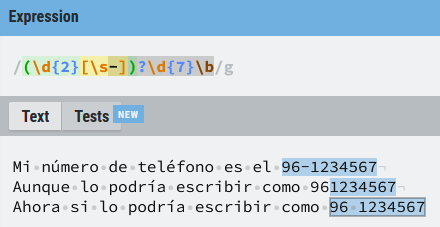
Una opción podría ser esta ((\d{2})?(-)?(?<!\s)\d{7}) de esta manera tanto el prefijo como el guion son opcionales y sólo son coincidencias válidas el número con prefijo separado por un guion y el número entero.
Pero... en la tercera línea hay una coincidencia y puede que no me interese que sea un número válido si no se indica el prefijo. No corras... no hemos visto todo el potencial de las expresiones regulares todavía, para eliminar esa coincidencia hay alternativas, como por ejemplo esta ((\d{2})?[-\s]?\d{7})), o esta (\b(\d{2})?[\s-]?(?<!\s)\d{7}\b), combinado algunas cosas ya vistas o esta otra expresión ((\d{2})?(-)?(?<!\s)\d{7}), de la que veremos su funcionamiento en la sección de Lookaround, no te preocupes si no entiendes todavía la nomenclatura.
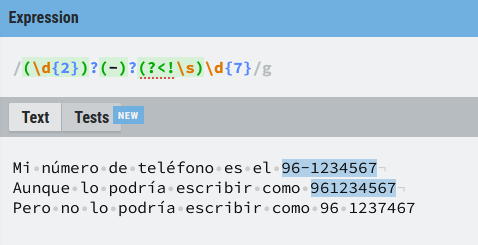
Como ves las pruebas con las expresiones regulares deben ser amplias, para evitar coincidencias no deseadas y el patrón lo más específico posible.
Hasta aquí la parte de conceptos básicos, con esto ya estamos preparados para afrontar nuestras primeras expresiones regulares, aunque nos ofrecen muchas más posibilidades con lo visto hasta ahora podría ser suficiente para empezar a usarlas. Pero aún quedan conceptos un poco más avanzados que ver que les dan mucha más potencia y versatilidad. Seguimos?
Conclusiones
Hasta aquí llega la primera de las entradas de esta serie de artículos sobre las expresiones regulares, hemos visto las capacidades básicas de las expresiones regulares incluyendo:
- Literales como (
hola, palabra, 55)... - El uso del (
.) que significa cualquier carácter menos el salto de línea. - El uso de (
[]) y los rangos con (-), por ejemplo ([a-z]). - Las clases de caracteres (
\s \S \w \w \d \D). - Los saltos de línea (
\n), (\r\n), (\r). - El uso de grupos (
()) para agrupar partes de la expresión, y por ejemplo aplicar un cuantificador. - Grupos de captura y grupos de captura con nombre, así como las backreferences para hacer referencia a ellos.
- Anclas para el inicio de palabra, texto, fin de palabra... (
^ $ \b \B). - Cuantificadores para repeticiones de tipo 0 o 1, 1 o más, 0 o más... (
? * + {n,m})
Con estas herramientas y algo de práctica puedes empezar a construir tus propias expresiones regulares, en el siguiente post de la serie veremos algunas cosas más avanzadas como expresiones regulares ávidas y perezosas, alternancia, condicionales, aserciones (lookahead y lookbehind), modificadores, entre otras cosas. No te la pierdas!
Referencias y recursos
Estupenda página para practicar expresiones regulares, cuenta con un resumen, un apartado para probar tus expresiones y varias opciones interesantes como la de explicar cada parte de la expresión regular:
Página similar a la anterior, que también funciona muy bien:
Página con información muy completa sobre expresiones regulares:

Otra página interesante con información de expresiones regulares:

Interesante herramienta que te puede ayudar a construir expresiones regulares:
 Olaf Neumann
Olaf NeumannWeb que genera los esquemas explicativos de casi cualquier expresión regular y que hemos usado en esta entrada del blog:

Te dejo algunos juegos por si quieres aprender o practicar expresiones regulares de una manera diferente:
