
AppDynamics → DEXTER → Kibana
Publicado por Daniel Extremiana Cea el
En este post vamos a hablar de cómo la herramienta DEXTER nos puede servir para exportar datos de AppDynamics para poder manejar la información a nuestro antojo en cualquier herramienta externa por ejemplo Kibana.
Esto es especialmente útil para aquellos casos en los que no tenemos una instalación on-premise sino SaaS.

DEXTER permite la extracción de toda o parte de la información de AppDynamics (Métricas, Snapshots, Business Transactions, Eventos, Flows, Información de performance…) en un rango de fechas determinado.
La información se genera a disco en formato JSON y .csv para poder ser posteriormente importada a otros medios de búsqueda o visualización como por ejemplo Kibana vía elasticsearch. Esto permite no solo almacenar la información de interés indefinidamente (reduciendo el coste de licencias por retención de datos) sino tratarla de forma personalizada.
Nota: Dexter también genera un montón de informes, dashboards, gráficos con mucha información en formato xlsx. Para este blog nos centraremos en los datos en formato JSON que son los que nos interesan a la hora de utilizar la información exportada en otras aplicaciones
Ejemplo de Report xlsx:
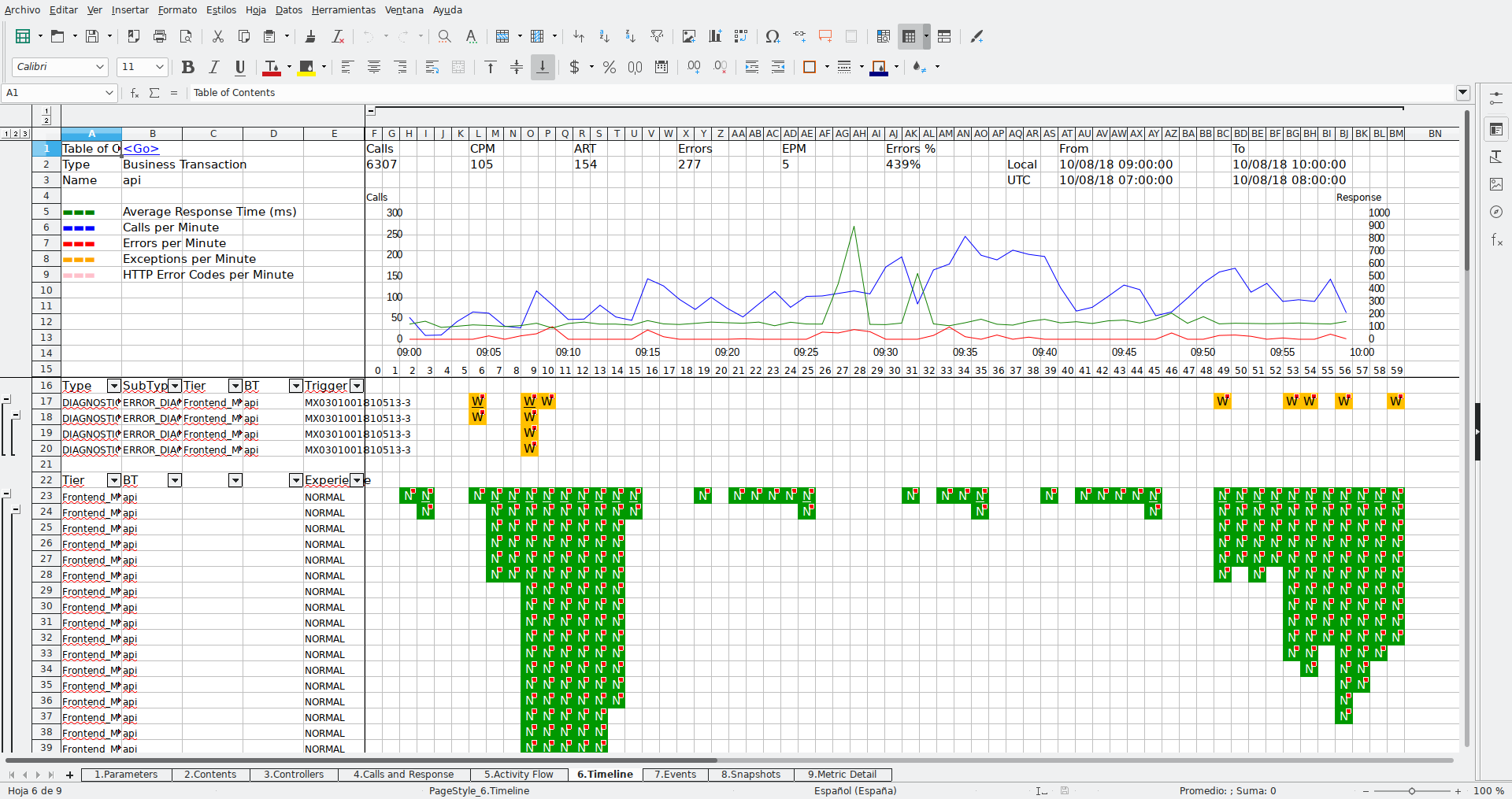
Requisitos para usar dexter en entorno linux
Instalar .net.
Instalar dexter.
En nuestro caso, vamos a hacer la instalación en nuestro entorno de test (Centos):
sudo yum update;sudo yum install aspnetcore-runtime-2.1
Seguidamente descargamos Dexter: Descargamos el zip con la última release del link superior y lo descomprimimos en nuestro entorno.
A continuación, debemos configurar qué datos queremos exportar y de qué controlador de appdynamics queremos extraer información. Para ello, se configura un job con extensión .json (en el link anterior se pueden ver todas las opciones de configuración).
Lo más importante sería indicar la instancia de AppDynamics (SaaS u OnPremise) a la que nos queremos conectar:
"Target": [
{
"Controller": "http://10.28.80.102:8090",
"UserName": "admin@customer1",
"UserPassword": "admin",
"Application": "AD-Financial",
"NameRegex": false,
"Type": "APM"
}
Es importante que el UserName sea en formato username@tenant
En el ejemplo anterior, tenemos los datos para conectar en nuestro entorno local.
El rango de Fecha / Hora del que queremos información:
"Input": {
"TimeRange": {
"From": "2018-08-10T09:00:00",
"To": "2018-08-10T10:00:00"
},Podemos limitar la información exportada por Tier, Nombre de aplicación, Tipo de Business Transaction….
También podemos activar o desactivar los informes en formato excel que son directamente para usuarios finales y que no nos interesan para este blog.
Exportar datos de AppDynamics con DEXTER
Ejecutamos el siguiente comando (en el caso de Centos):
dotnet exec netcoreapp2.0/AppDynamics.Dexter.dll -j net471/MyJob.jsonEl informe puede durar unos minutos según la cantidad de información a exportar. Finalmente se genera en nuestra home el directorio AppD.Dexter.Out con la siguiente estructura: jobname/Data/controller-name/application-name Y dentro las siguientes carpetas: CFG - Configuración ENT - Entorno EVT - Eventos FLOW - Flujos METR - Métricas SNAP - Snapshots Para este ejemplo cogeremos SNAP que contiene los snapshots para la aplicación de alimentación seleccionada.
/home/aplicaciones/AppD.Dexter.Out/.../Data/e.../Alimentacion.178015/SNAP/snapshots.201808100700-201808100800.jsonInstalamos ElasticSearch
Tenemos todos los pasos y opciones en este link, pero básicamente se trataría de hacer:
sudo yum install elasticsearch
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable elasticsearch.service
sudo systemctl start elasticsearch.serviceComprobamos que elasticsearch está instalado y corriendo correctamente:
curl -XGET 'http://localhost:9200'
{
"name" : "_vYW4yw",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "UgvuMu4EQx60kCNjeR-oIg",
"version" : {
"number" : "6.3.2",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "053779d",
"build_date" : "2018-07-20T05:20:23.451332Z",
"build_snapshot" : false,
"lucene_version" : "7.3.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}Preparar export para ser importado en ElasticSearch
Para poder importar los datos generados en formato JSON a ElasticSearch debemos adaptar la exportación ya que para importar en modo Bulk, necesitamos que haya un salto de linea por cada bloque y que tengamos el índice antes de cada linea:
cat snapshots.201808100700-201808100800.json | jq -c '.[]' > bulk.json
cat bulk.json | while read -r line; do echo "{\"index\": {}}"; echo $line; done > bulk-ready.jsonImportar datos en ElasticSearch
Finalmente ya tenemos en bulk-ready.json todas las snapshots listas para ser importadas en elasticsearch.
Creamos el índice: en nuestro caso le llamaremos “ind”
curl -XPUT 'http://localhost:9200/ind'Importamos las snapshots del fichero bulk-ready.json en el índice “ind” dentro del type que vamos a llamar “snap”
curl -XPOST localhost:9200/ind/snap/_bulk?pretty --data-binary @bulk-ready.json -H 'Content-Type: application/json'Una vez importadas tenemos la siguiente informacion:
[aplicaciones@vat-ot-appd0001 SNAP]$ curl -X GET localhost:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open ind K5YxouKVTsO3cEe813e8fw 5 1 4557 0 2.3mb 2.3mb
green open .kibana N1t04BDNTdCmLCIkaT67cQ 1 0 4 0 23.3kb 23.3kbInstalar kibana
sudo yum install kibana
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable kibana.service
sudo systemctl start kibana.serviceSi Kibana ha arrancado correctamente lo tendremos escuchando en el puerto por defecto 5601
NOTA: Es importante asegurarse de que hemos abierto el firewall para el acceso al puerto 5601 desde el navegadorNOTA2: Es importante asegurarse de que tenemos el puerto 5601 mapeado a 0.0.0.0 y no a localhost para poder acceder desde fuera. (En mi caso he tenido que actualizar el fichero: /etc/kibana/kibana.yml)
Añadiendo lo siguiente.
server.host: "0.0.0.0"
netstat -an|grep 5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTENVisualizar datos de ElasticSearch en Kibana
Para acceder a Kibana introducimos en nuestro navegador la ip y puerto:
Si accedemos a "Management" -> "Index Management" vemos que Kibana detecta automáticamente nuestro índice creado en ElasticSearch.
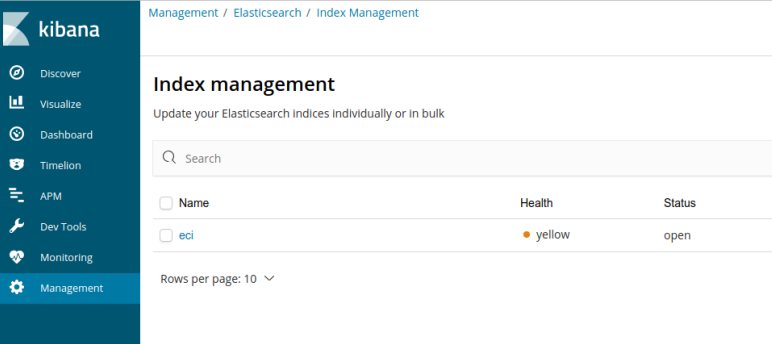
Seleccionamos nuestro índice y seguimos adelante.
Ahora Kibana ya dispone de nuestros datos del índice y podemos hacer reports o ejecutar queries sobre los datos contenidos en el índice. Para probar hacemos un chart mostrando el user experience que han tenido los usuarios.
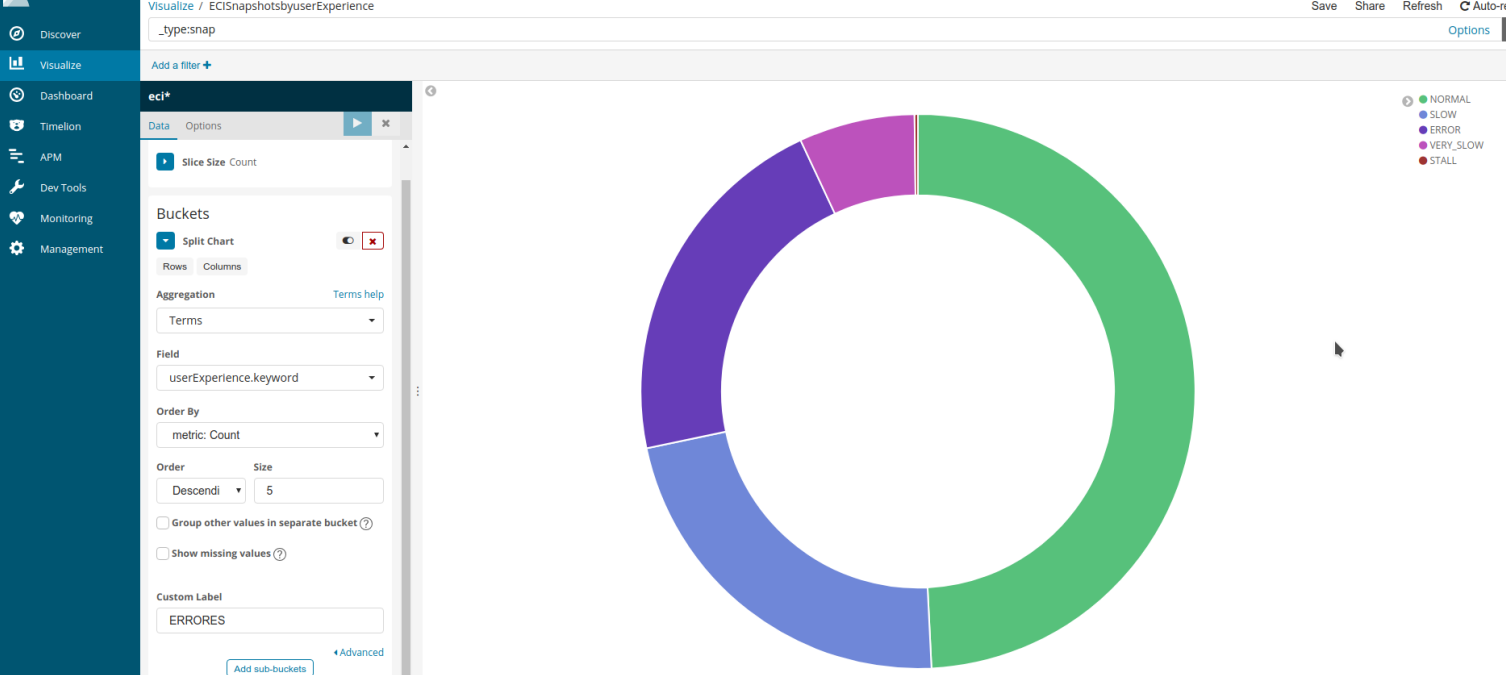
Vemos que le 50% de las snapshots se han ejecutado de forma NORMAL, y vemos el resto de las que se han ejecutado SLOW, ERROR, VERY SLOW o STALL.
Podemos tambien por ejemplo agrupar por tipo de business transaction y user experience:
De esta forma vemos agrupados para las busines transactions "buscar" y para "Food"
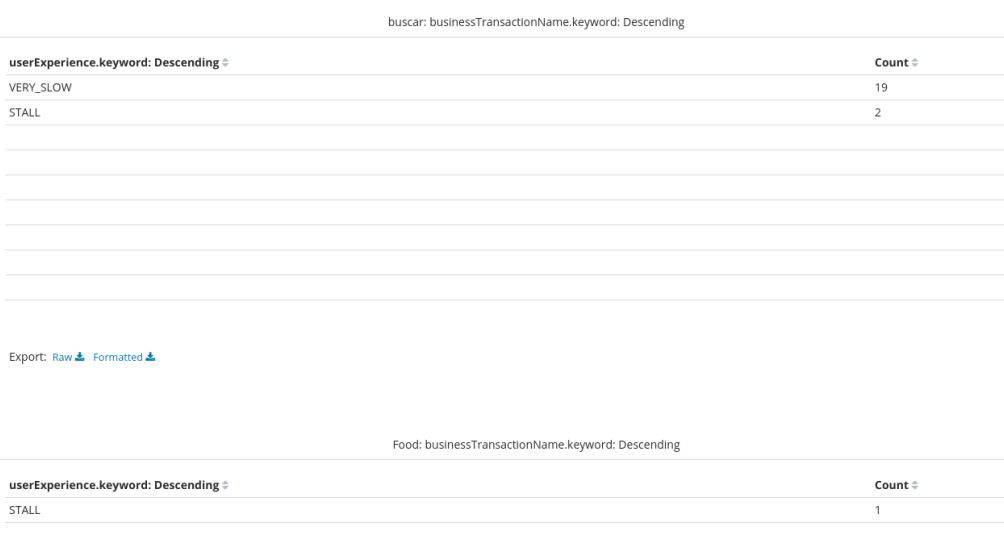
Conclusión
En definitiva, los datos exportados con DEXTER los tenemos a nuestra disposición sin límite de tiempo de retención y para usarlos en la herramienta que más nos guste.