
PoC Liferay 7 GA5 en cluster
Publicado por Antonio Javier Ortega Pérez el
Después de un largo tiempo con Liferay 6 y de los varios anuncios y noticias sobre las nuevas funcionalidades de Liferay 7, esta versión se publicó finalmente en Mayo 2017. Sus nuevas funcionalidades y reingeniería en cuanto a arquitectura (como OSGi, o el utilizar el paradigma SPA de base) resultaban muy interesantes, pero había dos pequeños detalles respecto a la versión commmunity que sorprendieron a la comunidad:
- Quitar el soporte a base de datos de pago.
- Quitar el soporte a cluster / alta disponibilidad
El hecho de quitar estas dos funcionalidades fue bastante notorio dado que existían en la versión 6.2 y el hecho de quitarlas para la versión 7 fue un ‘esfuerzo’ por parte de Liferay. Es por esto que, al lanzar la versión CE GA5 de Liferay, descubrimos gratamente que habían vuelto a soportar la alta disponibilidad en la versión community.
Es este artículo comentarnos una pequeña prueba de concepto sobre la instalación de Liferay 7 CE GA 5 en cluster.

Infraestructura
Por simplicidad toda la prueba se realizó utilizando varias máquinas virtuales montadas sobre una misma infraestructura física.
Infraestructura hardware física
La máquina física utilizada tenía las siguientes características:
- CPU Inter Core i7 4790K (4 cores / 8 threads)
- Memoria: 32 Gb RAM en cuatro módulos de doble canal.
- Disco duro: SSD Samsung 960 EVO PCIe NVME
Infraestructura virtual
Sobre esa infraestructura se realizó la siguiente configuración de máquinas virtuales:
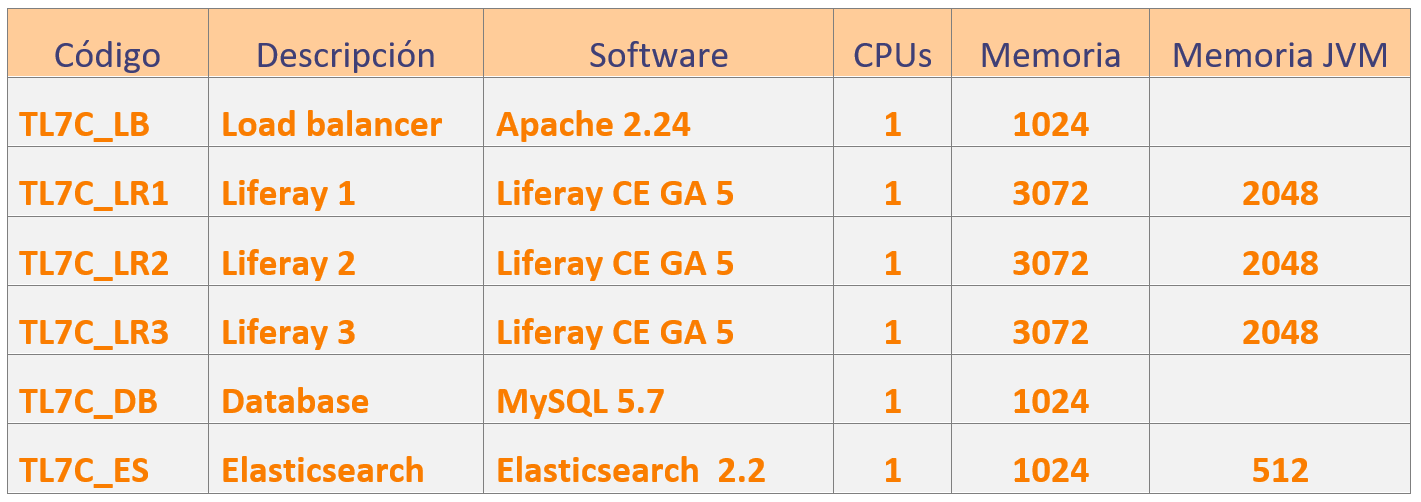
Resumen de la instalación
En este punto se asume que ya se sabe realizar una instalación en cluster de Liferay 7 (cuyos pasos son muy similares a Liferay 6) pero igualmente, denotaremos los puntos más destacados.
Para realizar la instalación de un cluster de Liferay hay que seguir los pasos típicos:
Base de datos común
Todos los nodos del cluster deben ‘atacar’ a la misma BBDD. Lo ideal sería una BBDD en cluster, pero en este caso se ha realizado con una única instancia de MySQL 5.7.
La instalación de la base de datos es muy sencilla y solo hay que tener en cuenta dos puntos importantes:
- Que el encoding de la BBDD sea UTF-8.
- Dar permiso para que la base de datos puede ser accedida por el usuario y las máquinas de Liferay.
Indexador en una máquina separada
Aunque Liferay 7 se distribuye con una versión incrustada (embeded) de Elasticsearch para entornos productivos se recomienda tener una instancia o cluster de indexación por separado. Notar que, además, cuando se trata de un cluster de Liferay es imprescindible que Elasticsearch se encuentre en una infraestructura separada para que así todos los nodos compartan la misma información de indexación.
Un hecho a destacar en este punto y que no explicita en la documentación oficial de Liferay es que es necesario instalar los siguientes plugins:
- bin/plugin install analysis-icu
- bin/plugin install analysis-kuromoji
- bin/plugin install analysis-smartcn
- bin/plugin install analysis-stempel
Si no se instalan estos plugins tendremos problemas al indexar assets que estén en diversos idiomas, dando excepciones como la siguiente:
[2018-01-23 13:30:54,281][DEBUG][action.bulk ] [Comet] [liferay-20116][3] failed to execute bulk item (index) index {[liferay-20116][LiferayDocumen
tType][com.liferay.document.library.kernel.model.DLFolder_PORTLET_31904], source[{"entryClassPK":"31904","publishDate_sortable":1516706608240,"hidden":"false","
ratings_sortable":0.0,"groupId":"20143","priority_sortable":0.0,"publishDate":"20180123112328","createDate_sortable":1516706608240,"title":"cats","uid":"com.lif
eray.document.library.kernel.model.DLFolder_PORTLET_31904","groupRoleId":"20143-20131","scopeGroupId":"20143","ratings":"0.0","title_sortable":"cats","modified"
:"20180123112328","modified_sortable":1516706608240,"expirationDate_sortable":9223372036854775807,"viewCount":"0","createDate":"20180123112328","expirationDate"
:"99950812133000","visible":"true","entryClassName":"com.liferay.document.library.kernel.model.DLFolder","roleId":["20123","20124"],"viewCount_sortable":0,"user
Name":"test test","priority":"0.0","userId":"20156","folderId":"31900","localized_title_zh_CN":"cats","localized_title_zh_CN_sortable":"cats","localized_title_e
s_ES":"cats","localized_title_es_ES_sortable":"cats","localized_title_ja_JP":"cats","localized_title_ja_JP_sortable":"cats","localized_title_iw_IL":"cats","loca
lized_title_iw_IL_sortable":"cats","localized_title_nl_NL":"cats","localized_title_nl_NL_sortable":"cats","localized_title_fi_FI":"cats","localized_title_fi_FI_
sortable":"cats","localized_title_ca_ES":"cats","localized_title_ca_ES_sortable":"cats","localized_title_hu_HU":"cats","localized_title_hu_HU_sortable":"cats","
localized_title_fr_FR":"cats","localized_title_fr_FR_sortable":"cats","localized_title":"cats","localized_title_en_US":"cats","localized_title_en_US_sortable":"
cats","localized_title_pt_BR":"cats","localized_title_pt_BR_sortable":"cats","localized_title_de_DE":"cats","localized_title_de_DE_sortable":"cats","stagingGrou
p":"false","companyId":"20116","treePath":["","31900","31904"],"status":"0"}]}
MapperParsingException[analyzer [smartcn] not found for field [localized_title_zh_CN]]
at org.elasticsearch.index.mapper.core.TypeParsers.parseAnalyzersAndTermVectors(TypeParsers.java:213)
at org.elasticsearch.index.mapper.core.TypeParsers.parseTextField(TypeParsers.java:250)
at org.elasticsearch.index.mapper.core.StringFieldMapper$TypeParser.parse(StringFieldMapper.java:161)
at org.elasticsearch.index.mapper.object.RootObjectMapper.findTemplateBuilder(RootObjectMapper.java:257)
at org.elasticsearch.index.mapper.object.RootObjectMapper.findTemplateBuilder(RootObjectMapper.java:243)
at org.elasticsearch.index.mapper.DocumentParser.createBuilderFromDynamicValue(DocumentParser.java:564)
at org.elasticsearch.index.mapper.DocumentParser.parseDynamicValue(DocumentParser.java:648)
at org.elasticsearch.index.mapper.DocumentParser.parseValue(DocumentParser.java:451)
at org.elasticsearch.index.mapper.DocumentParser.parseObject(DocumentParser.java:271)
at org.elasticsearch.index.mapper.DocumentParser.innerParseDocument(DocumentParser.java:131)
at org.elasticsearch.index.mapper.DocumentParser.parseDocument(DocumentParser.java:79)
at org.elasticsearch.index.mapper.DocumentMapper.parse(DocumentMapper.java:304)
at org.elasticsearch.index.shard.IndexShard.prepareCreate(IndexShard.java:500)
at org.elasticsearch.index.shard.IndexShard.prepareCreateOnPrimary(IndexShard.java:481)
at org.elasticsearch.action.index.TransportIndexAction.prepareIndexOperationOnPrimary(TransportIndexAction.java:214)
at org.elasticsearch.action.index.TransportIndexAction.executeIndexRequestOnPrimary(TransportIndexAction.java:223)
at org.elasticsearch.action.bulk.TransportShardBulkAction.shardIndexOperation(TransportShardBulkAction.java:326)
at org.elasticsearch.action.bulk.TransportShardBulkAction.shardUpdateOperation(TransportShardBulkAction.java:389)
at org.elasticsearch.action.bulk.TransportShardBulkAction.shardOperationOnPrimary(TransportShardBulkAction.java:191)
at org.elasticsearch.action.bulk.TransportShardBulkAction.shardOperationOnPrimary(TransportShardBulkAction.java:68)
at org.elasticsearch.action.support.replication.TransportReplicationAction$PrimaryPhase.doRun(TransportReplicationAction.java:595)
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37)
at org.elasticsearch.action.support.replication.TransportReplicationAction$PrimaryOperationTransportHandler.messageReceived(TransportReplicationAction.j
ava:263)
at org.elasticsearch.action.support.replication.TransportReplicationAction$PrimaryOperationTransportHandler.messageReceived(TransportReplicationAction.j
ava:260)
at org.elasticsearch.transport.TransportService$4.doRun(TransportService.java:350)
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Notar que estos plugins ya vienen instalados en la versión embedded de Elasticsearch en Liferay.
Documents and Media
Para un entorno Liferay en cluster se debe configurar la funcionalidad de Documents and Media apropiadamente utilizando su correspondiente store y con un soporte ‘hardware’ apropiado, esto es sobre una NAS, SAN, JCR, BBDD, etc … En definitiva, un sistema que permita que varios flujos lean el mismo fichero, bloqueos, etc… En este caso, se ha realizado de forma muy sencilla (aunque no recomendada), y es creando en cada servidor Liferay una conexión a una carpeta compartida en la máquina de BBDD.
Load balancer
El balanceador de carga será una máquina con Apache 2.4. Notar que en entornos reales la configuración de los balanceadores puede ser muy variable, por ejemplo, se puede dar que inicialmente haya balanceadores hardware (Cisco, F5, etc.) y luego varios balanceadores software (Apache, Nginx, etc.).
Para hacer el balanceo por Apache hay varias opciones, se puede utilizar el clásico modjk o bien modproxyajp o modproxyhttp. El primero es bastante antiguo, mientras que los dos siguientes son más modernos y soportados a partir de la versión 2.2 de Apache. Los módulos modproxyajp y modproxy_http son muy similares, lo que les diferencia es el protocolo de comunicación que se utiliza entre Apache y Tomcat (ajp o http respectivamente).
Para este ejemplo hemos utilizado modproxyajp con la siguiente configuración:
LoadModule proxy_module modules/mod_proxy.so
LoadModule proxy_ajp_module modules/mod_proxy_ajp.so
LoadModule proxy_balancer_module modules/mod_proxy_balancer.so
<VirtualHost *:80>
ServerName localhost.localdomain
ErrorLog c:/apache24/logs/ajp.error.log
CustomLog c:/apache24/logs/ajp.log combined
<Proxy *>
AddDefaultCharSet Off
Order deny,allow
Allow from all
</Proxy>
ProxyPass / balancer://ajpCluster/ stickysession=JSESSIONID
ProxyPassReverse / balancer://ajpCluster/ stickysession=JSESSIONID
<Proxy balancer://ajpCluster>
BalancerMember ajp://TL7C_LR1:8009 route=node-01
BalancerMember ajp://TL7C_LR2:8009 route=node-02
BalancerMember ajp://TL7C_LR3:8009 route=node-03
ProxySet lbmethod=byrequests
</Proxy>
</VirtualHost>
Configuración Liferay
Notar que esto es una configuración básica, por ejemplo, en un entorno productivo el método de balanceo “byrequests” no sería el más recomendado sino bybusiness , bytraffic o heartbeat, pero para una PoC se ha considerado suficiente.
La configuración de Liferay tiene que cubrir todo lo comentado anteriormente:
- Conexión con base de datos.
- Conexión con instancia separada de Elasticsearch
- Configuración de Documents and Media.
- Activar caché en cluster
- Configuración del conector Tomcat con el balanceador
Esta configuración se realizará en varios ficheros, empezando por el portal-ext.properties:
jdbc.default.url=jdbc:mysql://TL7C_DB:3306/lportal?useUnicode=true&characterEncoding=UTF-8&useFastDateParsing=false
jdbc.default.driverClassName=com.mysql.jdbc.Driver
jdbc.default.username=root
jdbc.default.password=qwertyui
cluster.link.enabled=true
dl.store.impl=com.liferay.portal.store.file.system.AdvancedFileSystemStore
web.server.display.node=true
Aquí solo he puesto las configuraciones más relevantes. Veamos la configuración de bbdd, la activación de cluster link para la caché distribuida, la selección AdvancedFileSystemStore como implementación de Documents and Media y el hecho de mostrar el nombre del servidor en el tema.
Siempre que se realiza una prueba en cluster es muy conveniente que tengamos información sobre a qué servidor estamos accediendo. Esto lo podríamos hacer con un desarrollo a medida, una plantilla ‘especial’, etc ... pero hay una opción mucho mas sencilla, que es la propiedad web.server.display.node=true, que precisamente muestra en el footer del tema el nodo al que estamos accediendo.
En Liferay 7 muchas funcionalidades se han encapsulado en módulos OSGi, y entre ellas se encuentran las “store” de Documents and Media y la indexación. Para configurar DaM con la Advanced File System Store primero hay que indicar en el portal-ext.properties que se va a utilizar esta store (como ya hemos visto), y luego añadir el siguiente fichero:
com.liferay.portal.store.file.system.configuration.AdvancedFileSystemStoreConfiguration.cfg
rootDir=Z:/l7store
com.liferay.portal.search.elasticsearch.configuration.ElasticsearchConfiguration.cfg
operationMode=REMOTE
transportAddresses=TL7C_ES:9300
Pruebas de carga
El objetivo principal que todo el mundo asocia a las pruebas de carga (o pruebas de stress) es saber cuántas peticiones puede atender un sistema correctamente, pero también hay otros objetivos secundarios:
- Saber cómo escala el sistema tanto verticalmente como horizontalmente. En este punto cabe recordar que por escalar verticalmente se suele entender poner ‘hardware más potente’, mientras que con escalar horizontalmente se suele entender poner más nodos/servidores. Entonces, el ver cómo escala un sistema se podría resumir como una sencilla pregunta de:
- Para escalabilidad vertical: Si con un hardware X tengo una respuesta Y, ¿con un hardware 2X (el doble de ‘potente’) consigo 2Y (el doble de rendimiento)?
- Para escalabilidad horizontal: Si con X servidores tengo una capacidad de respuesta Y, ¿Con 2X servidores tendré una capacidad de respuesta 2Y?
- Saber cómo afecta al servicio el hecho de que haya más carga. Si en condiciones digamos ‘holgadas’ del sistema una petición (por ejemplo, cargar una página) tarda 1 segundo, bajo situaciones de gran carga ¿El servicio seguirá respondiendo en un segundo o bien tardará 10 segundos? Y la pregunta inmediata que nos tenemos que hacer es: ¿Es ‘aceptable’ esa calidad de servicio?
Portal de ejemplo
Para hacer las pruebas de carga se ha hecho un portal sencillo con cuatro páginas:
- La página ‘Welcome’ por defecto de Liferay.
- Web Content Página que muestra contenidos web básicos tipo ‘Lorem ipsum’ mediante portlets Asset Publisher.
- Documents. Página con dos portlets “Categories navigation” y un “Asset Publisher”. En Document and Media se han añadido un conjunto de imágenes triviales por tipologías: coches, motos, perros y gatos. En esta página por defecto se muestran todos y se permite filtrar por la categoría que se les aplica. Lo importante de este hecho es notar que de base se muestran todas las imágenes (17).
- Blog. Página con el portlet de blogs y dos entradas de blog sencillas.
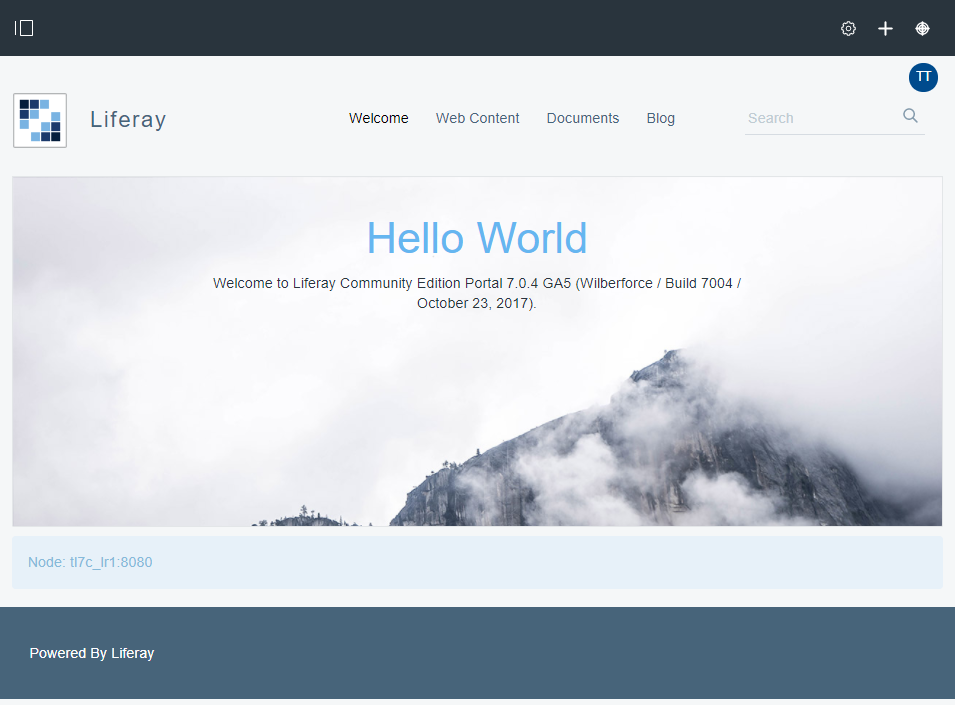
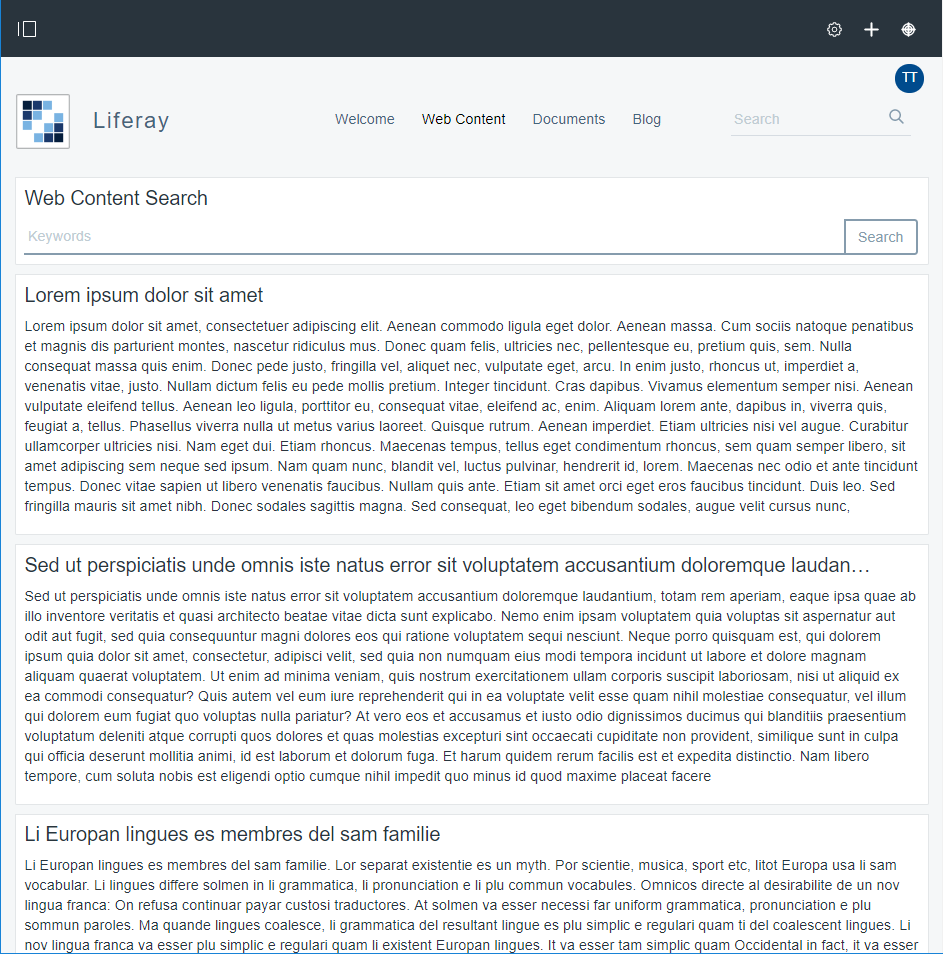
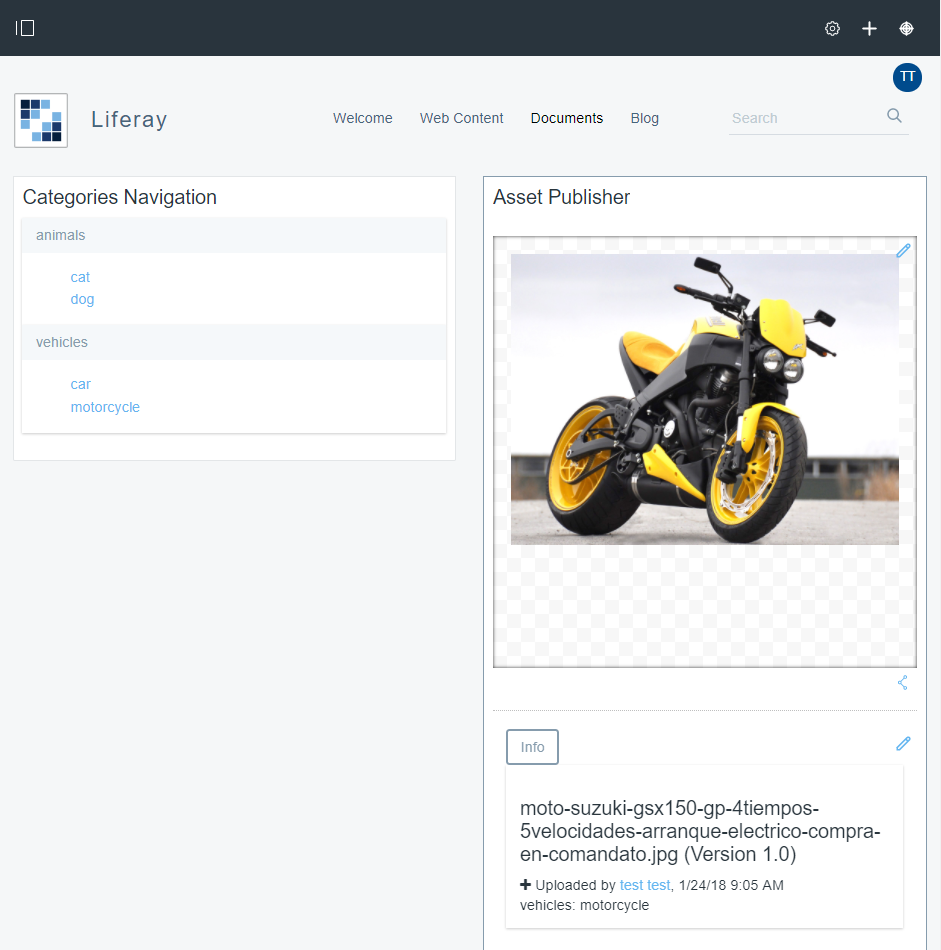
Definición del plan de pruebas
Las pruebas de stress se realizarán con el programa jMeter llamando a cada una de las páginas anteriores con un segundo de tiempo de espera entre peticiones. El árbol de configuración de jMeter se muestra más adelante.
Notar que se utiliza un “Interleave controller” entre las cuatro páginas para que así, la carga de cada página se distribuya entre cada servidor. Recordar que por simplicidad como método de balanceo utilizábamos ‘byrequest’, que es lo mismo que decir un ‘Round Robin’, por tanto, si hubiéramos elegido múltiplos de tres páginas (3,6,9, etc.) como conjunto de pruebas de stress podríamos caer en el hecho de que cada página la atendiese un servidor:
- Distribución de páginas por servidor para conjunto de pruebas de tres páginas:

En este caso el servidor 1 siempre atiende peticiones de la página 1, el servidor 2 siempre atiende peticiones de la página 2, y el servidor 3 siempre atiende peticiones de la página 3.
- Distribución de páginas por servidor para conjunto de pruebas de cuatro páginas:

- Distribución de páginas por servidor para conjunto de pruebas de cinco páginas:

- Distribución de páginas por servidor para conjunto de pruebas de seis páginas:

Notar que en este caso el servidor 1 siempre atiende peticiones de la página 1 y 4, el servidor 2 siempre atiende peticiones de la página 2 y 5, y el servidor 3 siempre atiende peticiones de la página 3 y 6.
Es por este hecho que hemos realizado unas pruebas con un conjunto de cuatro páginas. Notar que igualmente podemos corroborar que está sucediendo esto echando un vistazo al *access.log de Tomcat:
"GET /web/guest/home HTTP/1.1" 200 25892
"GET /web/guest/web-content HTTP/1.1" 200 41367
"GET /web/guest/documents HTTP/1.1" 200 184195
"GET /web/guest/blog HTTP/1.1" 200 38409
"GET /web/guest/home HTTP/1.1" 200 25892
"GET /web/guest/web-content HTTP/1.1" 200 41367
"GET /web/guest/documents HTTP/1.1" 200 184195
"GET /web/guest/blog HTTP/1.1" 200 38409
"GET /web/guest/home HTTP/1.1" 200 25892
"GET /web/guest/web-content HTTP/1.1" 200 41367
"GET /web/guest/documents HTTP/1.1" 200 184195
"GET /web/guest/blog HTTP/1.1" 200 38409
"GET /web/guest/home HTTP/1.1" 200 25892
"GET /web/guest/web-content HTTP/1.1" 200 41367
"GET /web/guest/documents HTTP/1.1" 200 184195
"GET /web/guest/blog HTTP/1.1" 200 38409
"GET /web/guest/home HTTP/1.1" 200 25892
"GET /web/guest/web-content HTTP/1.1" 200 41367
"GET /web/guest/documents HTTP/1.1" 200 184195
Ejecución del plan de pruebas
Para empezar correctamente lo que debemos hacer es saber cuál es el punto de partida y para ello haremos la prueba más simple que se pueda imaginar (la cual muchas veces no se hace), y es un hilo contra una máquina.
Seguidamente lo que haremos es ver cuál es la carga máxima de un servidor, pero:
- Sin llegar a la saturación.
- Sin tener errores (o al menos que estos sean una proporción despreciable).
- Sin perder demasiada ‘calidad de servicio’.
Test de 1 máquina
1 máquina / 1 thread
Lo importante de esta prueba es saber el punto de partida, es decir, el tiempo que tardan las páginas en condiciones ‘holgadas’. Con esta información también podemos ver cuáles son las páginas más ligeras y las más pesadas. Por ejemplo, vemos que ‘Home’ y ‘Web Content’ son muy rápidas, luego viene ‘Blogs’, y finalmente la página de Documentos, que comparativamente es mucho más pesada.
Con esta prueba vemos que evidentemente la CPU está muy holgada.
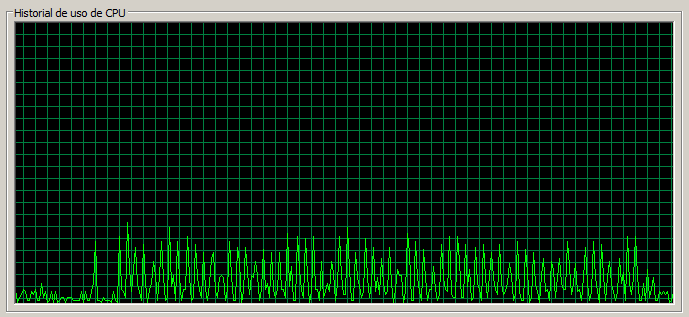

1 máquina / 20 threads
Ahora probamos con 20 threads y vemos que las páginas tardan bastante más en cargar, casi 5 veces más (Documents ha pasado a casi un segundo), pero igualmente siguen siendo unos tiempos muy buenos (83ms, 98ms, 944ms, 224ms).
Notar que en Documents se da una tasa de error de 0,2%, que, sobre 508 peticiones corresponde a 1 error, lo cual lo podemos dar como despreciable sobre un conjunto de 508 peticiones a Documents y de 2051 en total.
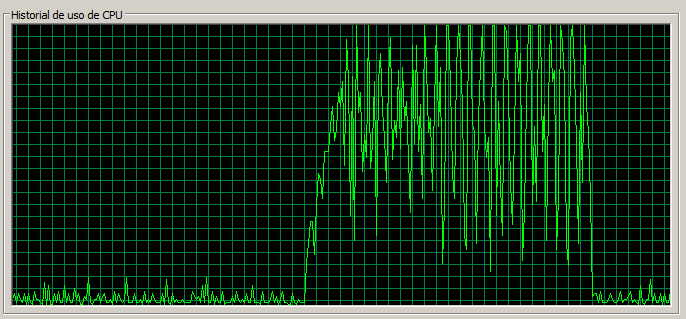

1 máquina / 30 threads
En este caso podemos ver que el número de errores se mantiene muy bajo los tiempos han crecido (la página Documents tarda 1,5s) y que el uso de CPU se acerca a la saturación.
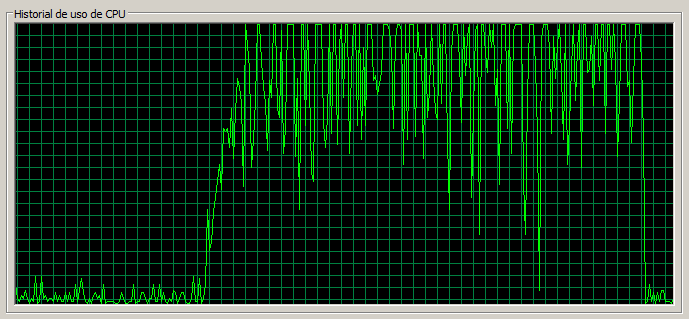

1 máquina / 40 threads
Aquí ya vemos que la CPU está muy saturada (uso de 100% continuado), los errores aumentan (2% en la página de Documents) y los tiempos también (2,5 segundos la página de Documents)
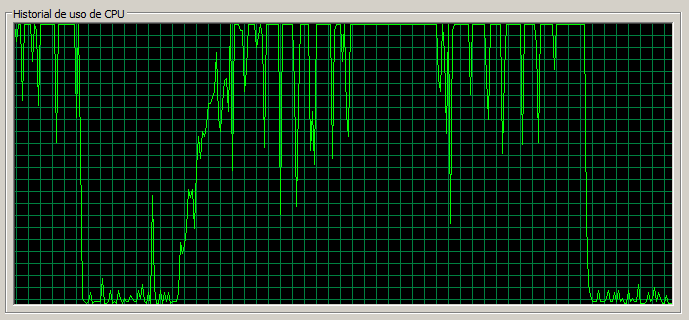

1 máquina / 50 threads
Con 50 threads vemos que empieza a degenerar bastante. La página de Documents tarda 4 segundos, lo cual ya comienza a ser mucho, y también se puede observar que la CPU está casi todo el tiempo saturada.
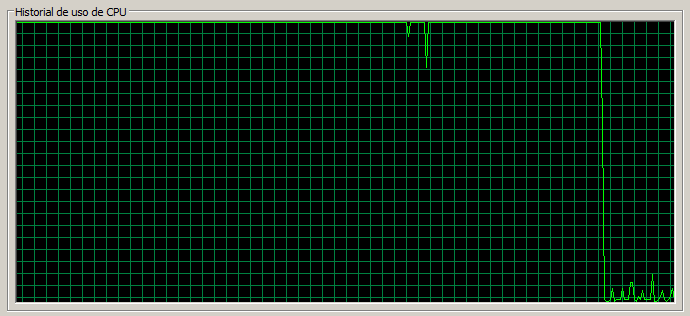

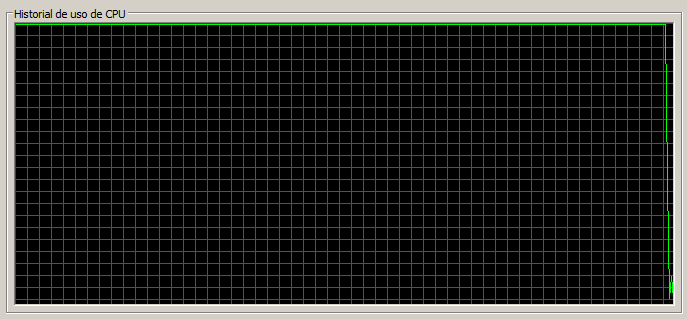
1 máquina / 100 threads
Por curiosidad vamos a ver qué ocurre con 100 threads, aunque ya es de suponer lo que ocurrirá. La CPU se encuentra totalmente saturada todo el tiempo, la página de Documents tarda una media de 11 segundos en cargar y la de Blog 3 segundos.

Corolario test de 1 máquina
Dados los diferentes análisis para un servidor nuestro punto de referencia para analizar la escalabilidad es que un servidor (tal y como lo hemos dimensionado) puede atender 30 usuarios. ¿Por qué? Pues porque simplemente así lo hemos decidido en base a nuestro criterio de tolerancia a fallos, calidad de servicio y saturación del servidor:
- La página más pesada (Documents) tarda 1,4 segundos (menos de dos).
- El total de errores es del 0,02%, que, sobre una muestra de 4000 es 1 error. Totalmente aceptable y despreciable.
- El uso de CPU se encuentra cercano al 100% pero pocas veces entra en saturación.
Test de 3 máquinas
3 máquinas / 1 thread
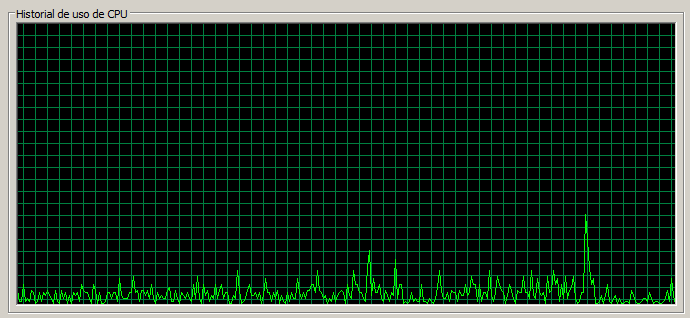
Este caso puede parecer trivial dado que es ‘holgadísimo’, pero no está de más realizarlo, sobre todo para comprobar si el hecho de añadir un elemento nuevo tiene afectación. Las pruebas anteriores se han realizado atacando directamente el servidor Liferay, sin embargo, a partir de ahora se realizarán accediendo al balanceador Apache. Además, este caso realmente no es demasiado útil dado que, si una petición ya ha sido respondida por un servidor, Apache no avanza el contador de Round Robin y la siguiente petición la volverá a enviar al mismo servidor, a la práctica, aun teniendo la configuración dada, todas las peticiones irán al mismo servidor. Esto se puede observar fácilmente accediendo a los logs de los servidores Liferay o bien simplemente mirando el uso de CPU de cada uno de los servidores.
En el caso mostrado todas las peticiones han sido atendidas por el tercer nodo.
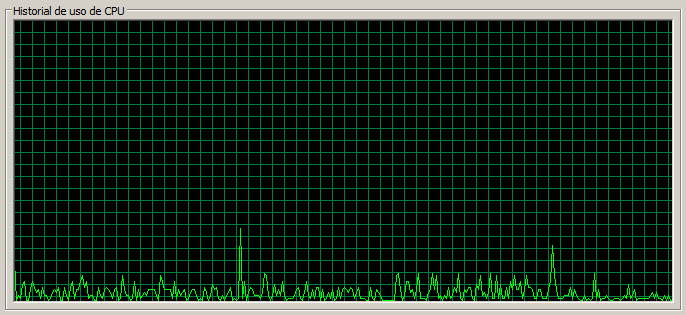
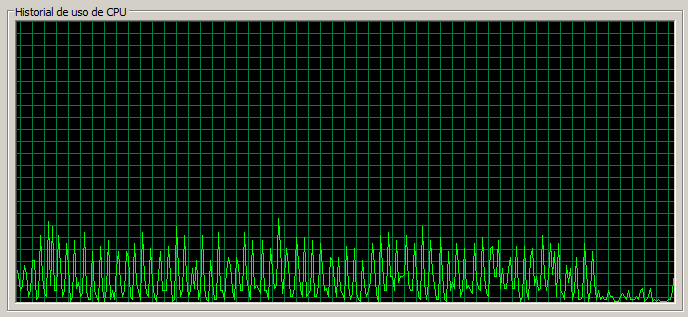

3 máquinas / 50 threads
En este caso vemos como la CPU llega al 100% en casos puntuales, pero en general se encuentra bastante holgada.
En cuanto a tiempos podemos observar como la página de Documents tarda una media de 0,7 segundos, algo menos que en el caso de 20 threads para 1 servidor.
Tenemos una tasa de error global de 0,04, que, sobre 120777 corresponde a 5 errores, lo cual entra en la consideración de ‘despreciable’.
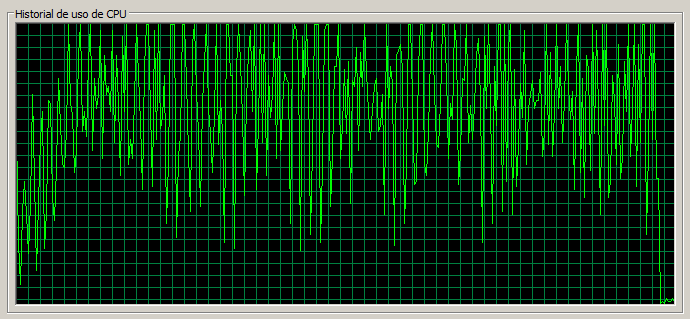
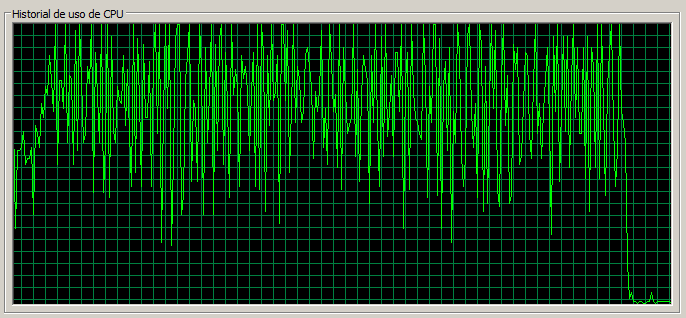
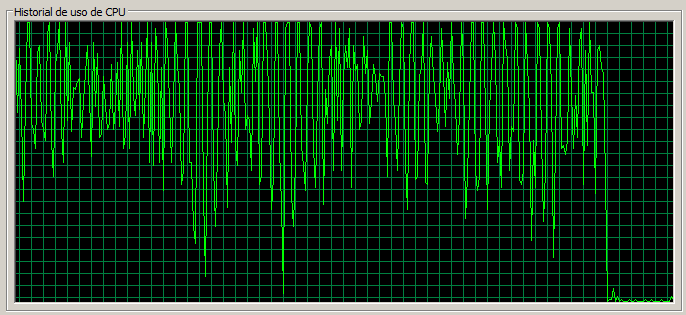

3 máquinas / 70 threads
En este caso la página de Documents se empieza a acercar a 1,5 segundos, que era el tiempo de referencia para 1 servidor con 30 threads. El uso de CPU también empieza ligeramente a acercarse a la saturación. La tasa de error global ha pasado de 0,04 a 0,29, lo cual es bastante significativo.
Por último, también remarcar que la página ‘Web Content’, aunque sigue teniendo un rendimiento muy bueno, se ha resentido bastante pasando a 248 ms, dado que para el caso de 1 servidor / 30 threads daba tiempos medios de 159 ms.
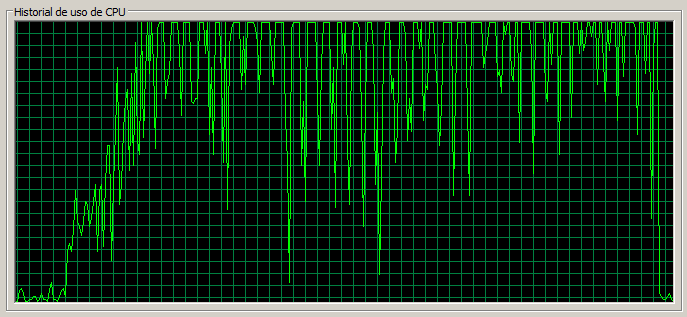
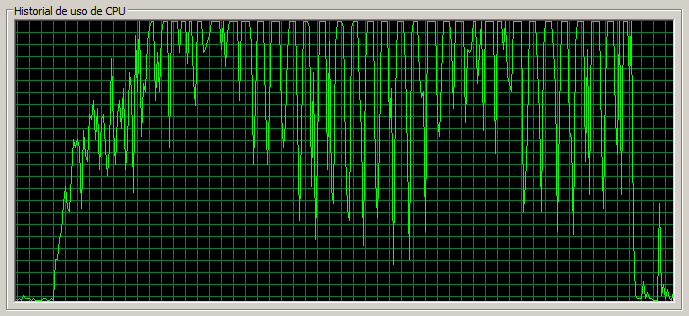
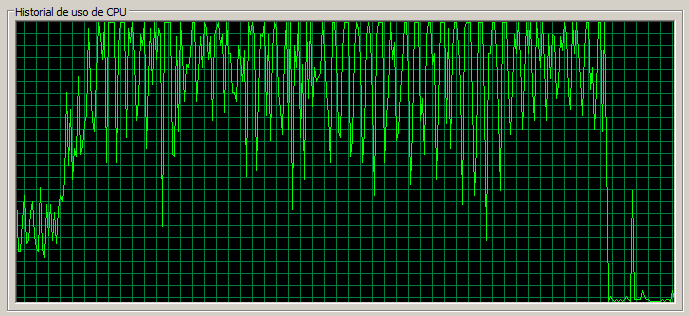

3 máquinas / 90 threads
Este escenario sería la contrapartida de nuestro punto de referencia de 1 servidor y 30 threads con 3 servidores y 90 threads.
Como vemos la página de Documents no se ha resentido mucho respecto el escenario anterior, ni tampoco la tasa de error, sin embargo, vemos como las páginas ‘ligeras’ (como la ‘Home’ y Web Content) sí que se han resentido bastante pasando a tardar una media de 0,5 segundos.
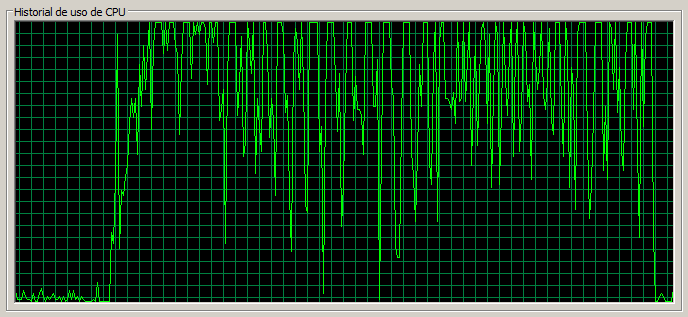
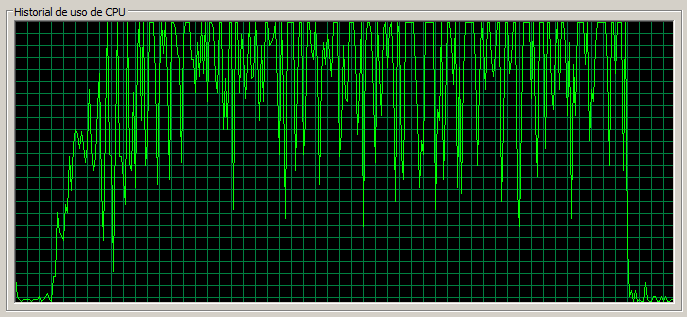
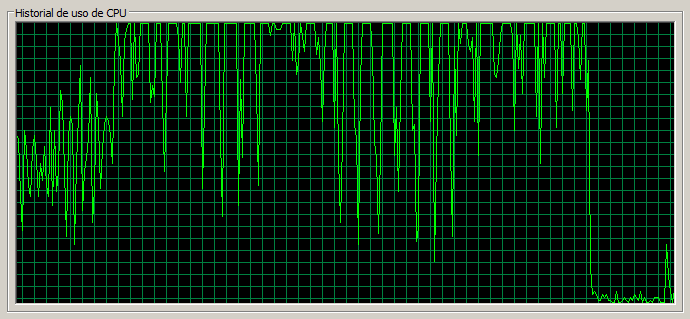

3 máquinas / 110 threads
En este caso las páginas ligeras se resienten mucho, pasando a tardar casi un segundo en cargar, y la tasa de errores ha aumentado mucho proporcionalmente. Notar que las páginas de Documents y Blog no se resienten tanto como las anteriores.
Notar también que la CPU en el nodo dos se encuentra muy saturada.
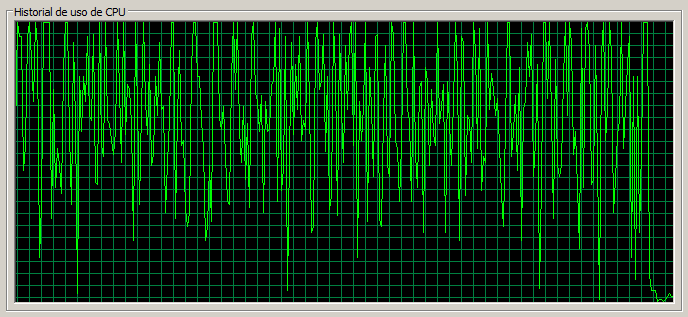
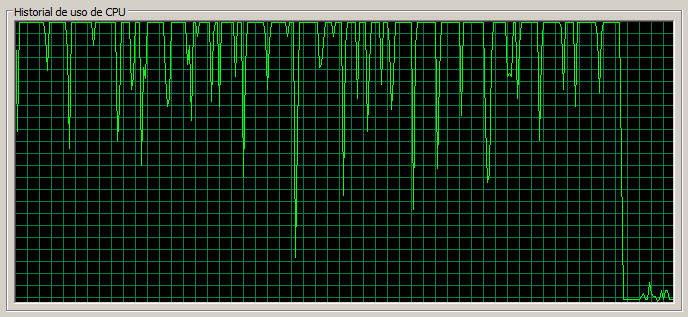
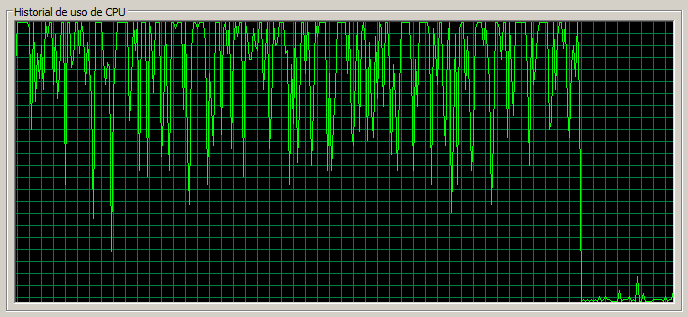

3 máquinas / 130 threads
En este escenario la tasa de errores es muy alta y se acerca al 1%. Las páginas sencillas tardan 1,3 segundos mientras que Documents pasa a tardar 3 segundos y la CPU en el nodo 1 está muy saturada.
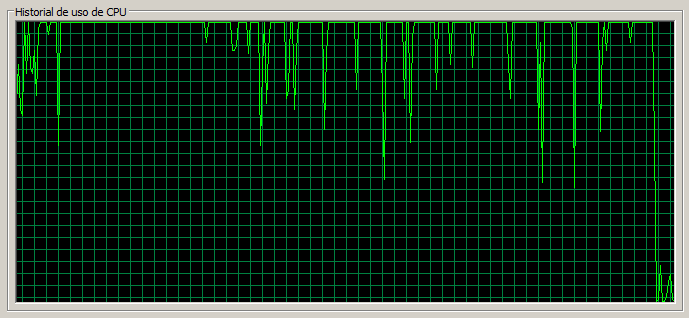
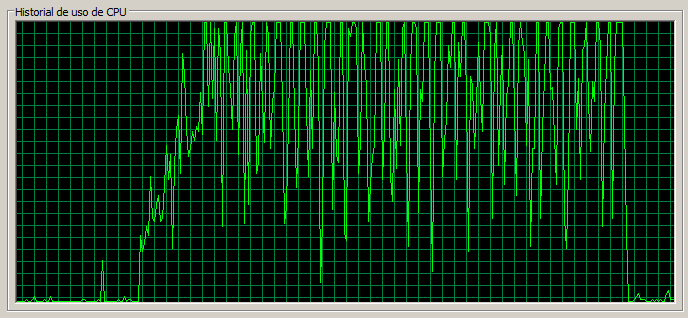
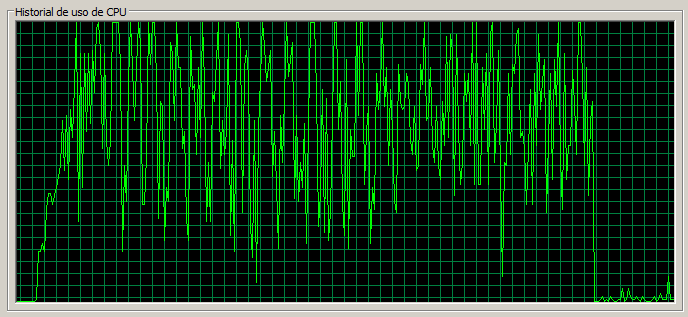

Corolario test de 3 máquinas
Una vez se han revisado los resultados para las pruebas de stress correspondientes a uno y tres servidores vamos a sacar conclusiones.
- A partir de cierto punto las páginas ligeras se resienten considerablemente, hecho que no ocurre con un servidor.
- En ocasiones la carga en un nodo es notoriamente superior.
- La escalabilidad es bastante lineal. Si comparamos el throughput de los dos test de referencia tenemos:
- 1 máquina / 30 threads: troughput de 18,2
- 3 máquinas / 90 threads: throughput de 40,0
Lo que indica que con 3 servidores tenemos una escalabilidad de 2,2 (en vez de 3x)
A título de comparación final volvemos a exponer los resultados de un servidor y 30 threads:
Comparado con tres servidores y 90 threads:
Aspectos a tener en cuenta
Aserciones en las mediciones
En estas pruebas se ha considerado error simplemente lo que jMeter considera error, que en la mayoría de los casos corresponde a una respuesta:
java.net.ConnectException: Connection refused: connect
at java.net.DualStackPlainSocketImpl.connect0(Native Method)
at java.net.DualStackPlainSocketImpl.socketConnect(Unknown Source)
at java.net.AbstractPlainSocketImpl.doConnect(Unknown Source)
at java.net.AbstractPlainSocketImpl.connectToAddress(Unknown Source)
at java.net.AbstractPlainSocketImpl.connect(Unknown Source)
at java.net.PlainSocketImpl.connect(Unknown Source)
at java.net.SocksSocketImpl.connect(Unknown Source)
at java.net.Socket.connect(Unknown Source)
pero habría que comprobar en detalle que es una respuesta correcta. Es este sentido se necesitaría añadir aserciones para comprobar que lo que realmente devuelve la petición es lo que espera el test.
Tipología de las pruebas
Un hecho a destacar es que estas pruebas de carga se han centrado en un portal que muestra información y es por ello que el portal de ejemplo se ha realizado en base a mostrar contenidos, y el análisis se ha centrado en los servidores Liferay. Pero nuestra infraestructura tiene más ‘piezas’ … ¿Qué ocurre con ellas? En este análisis no hemos tratado la carga del load balancer, la base de datos o el indexador dado que su carga era mínima y no afectaba a los datos globales, pero, como nuestro objetivo es hacer unas pruebas que simulen un escenario real y este escenario real fuese de una naturaleza diferente, deberemos recrear esas pruebas acorde a la naturaleza de la realidad.
Por ejemplo, si hubiéramos tenido un escenario con una gran cantidad de datos de entrada de los usuarios (como los portales colaborativos con multitud de blog, fórums, wikis, etc.) hubiésemos tenido que crear un conjunto de pruebas acordes a esta realidad y en este caso hubiese sido importante monitorizar también el indexador, la base de datos y el sistema de respaldo de DaM.
Relativo al escenario de mostrar contenido hay que comentar que todo el contenido utilizado a fin y al cabo se encuentro “cacheado” en los servidores dado que es muy poco contenido y muy concreto, por tanto, no se accede a DaM ni a la BBDD para consultar meta-información.