
Sobreviviendo al S3pocalypse
Publicado por Sergio Lecuona el
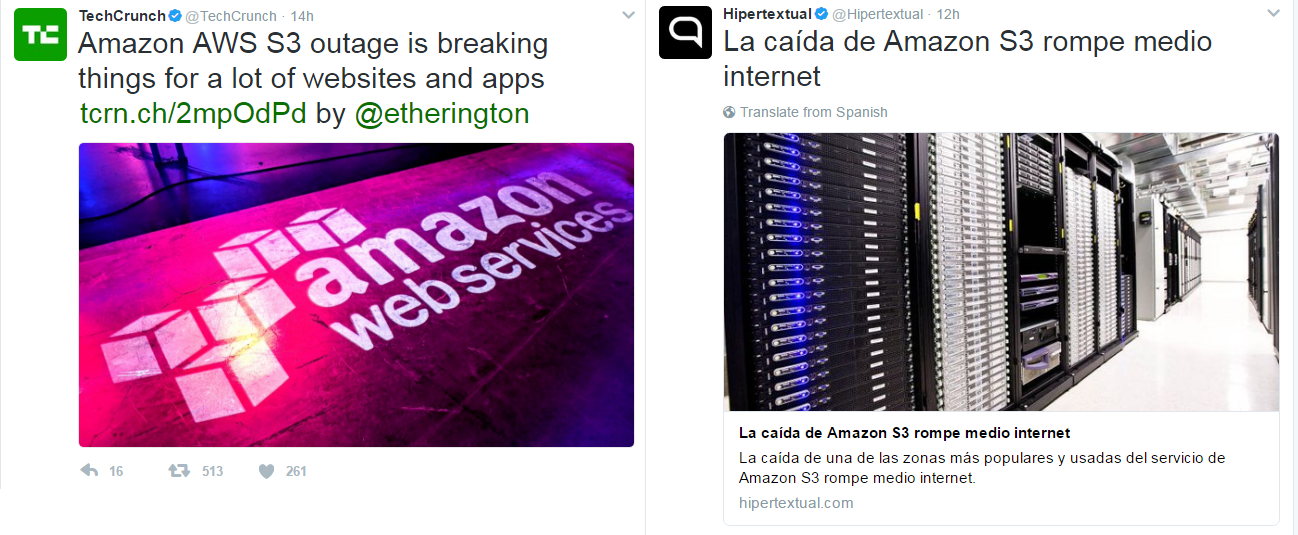
Es martes por la noche en Madrid, estamos sentados tranquilamente en el sofá viendo nuestra serie favorita de Netflix cuando con la otra mano cogemos el móvil y abrimos Twitter para ver el primer aviso de la que va a ser una noche interesante:


Rápidamente el problema empieza a hacerse viral y no faltan las páginas que hablan casi del fin del mundo, del fin de la sociedad tal y como la conocemos y la caída de internet:
La primera comprobación sencilla era ir al dashboard de Amazon AWS donde muestra el estado de los servicios, y ahí comprobamos que todo funciona como debe, no hay ninguna incidencia y según la información reflejada todo está operando con normalidad:
https://status.aws.amazon.com/
Pero, ¡sorpresa! El panel de AWS que nos sirve para monitorizar el estado de los servicios de AWS… hace uso de los servicios de AWS, ¡entre ellos el S3! Así que nos avisan de que la información reflejada no es válida. Por favor, AWS, esto hay que cambiarlo…

Mientras permanecemos en la incertidumbre de qué está ocurriendo pasamos a revisar en qué medida nos está afectando. Por suerte, todos nuestros servicios alojados en AWS están en la región eu-west-1 (Irlanda) y la incidencia está ceñida a la región de Estados Unidos Us-East-1. Pero, aunque en ese sentido podamos estar tranquilos, el daño parece enorme: miles de sitios web están caídos: Trello, Slack, IFTT, etc.
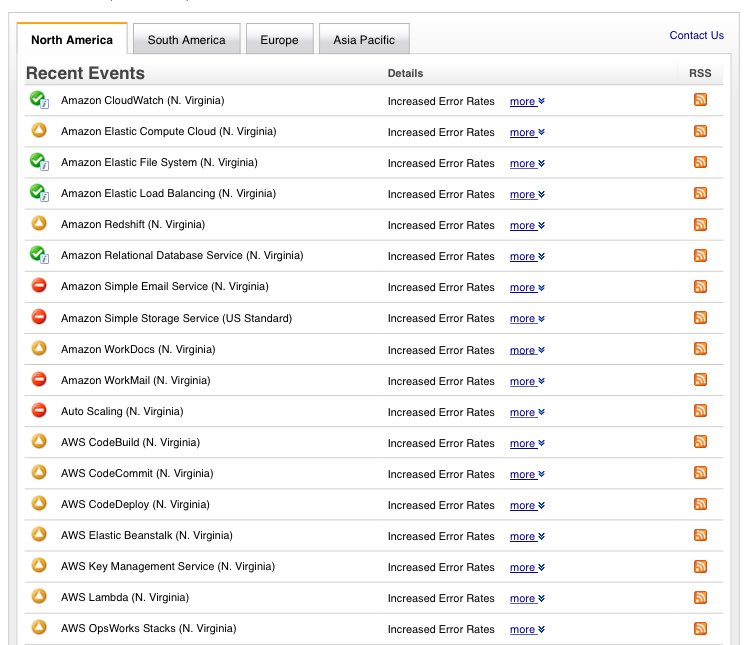
Pasada una hora aproximadamente desde el inicio de los problemas, consiguieron recuperar el dashboard de estado de los servicios y se vio que el problema era mayor de lo imaginado. Los errores en S3 estaban impactando sobre el funcionamiento de otros servicios y provocaba fallos en Lambdas, Simple Email Service, Workmail, Autoescalados…

Así nos decían que luce el apocalipsis:
Al menos parecía que el problema estaba acotado, y tres horas después todo había terminado. S3 volvía a funcionar correctamente en la región afectada y los servicios volvían a la normalidad:
Una vez arreglado y con todo en calma vamos a entender mejor qué ha pasado, y para eso mejor empezamos con lo que quizá algunos se estén preguntando:
¿Qué es S3?
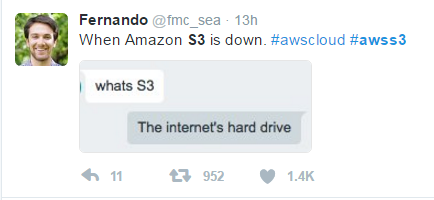
Una simplificación bastante graciosa se vio en Twitter cuando la gente se hacía la misma pregunta:
Pero es mucho más que eso. Amazon Simple Storage Service (S3 para los amigos) es “un servicio de almacenamiento sencillo que ofrece a los desarrolladores de software una infraestructura de almacenamiento de datos de gran escalabilidad, fiable y de baja latencia con costos muy bajos.” (src: https://aws.amazon.com/es/s3/faqs )
No parece tan grave entonces, podríamos pensar que una caída de S3 implicaría que no podemos acceder a ficheros. Pero este servicio también dispone de una opción para utilizarlo como “website” alojando nuestro contenido estático en un “bucket”, permitiendo que nuestros frontales no necesiten servidores y estén replicados. Además, nos garantizan unos SLA impresionantes:
https://aws.amazon.com/s3/sla/
Y sí, ahí dicen que S3 garantiza una DISPONIBILIDAD del 99,9% y una DURABILIDAD de 99.999999999%. Así que, según esas condiciones, a AWS no le va a salir barata la caída de ayer y se tendrá que hinchar a recibir solicitudes de créditos como compensación.
Pero pongo en mayúsculas las palabras DISPONIBILIDAD y DURABILIDAD porque esa noche hubo muchos comentarios erróneos al respecto:

Lo siento Peter, no estás del todo en lo cierto.
Efectivamente AWS garantiza que solo tendrás una pérdida de información del 0.000000001% de los objetos, pero el “#S3pocalypse” (¡llegó a ser trending topic!) no fue un problema de durabilidad (de pérdida de información), sino de “acceso” a la información. Así que realmente aplicacaría el 99,99% de “disponibilidad”.
Si tenemos en cuenta que estuvieron caídos unas 4 horas, y suponemos (esperamos) que no volverá a caer en todo el año, habrán estado disponibles un 99,95% del tiempo (bastante bien a pesar del ruido).
Una vez he conseguido que retoméis la confianza en S3 y sus bondades tendremos que esperar para ver cuál fue la causa raíz cuando AWS libere la información. Aunque todo indica que se trató de problemas de comunicaciones, y parece que lo tenían ya bastante acotado:

Entonces, ¿podemos confiar en AWS y S3?
Sí. La respuesta es fácil. Sí.
A pesar de todo el ruido que ha hecho esta crisis, S3 sigue manteniéndose en niveles de disponibilidad impresionantes. La capacidad de gestión del ciclo de vida, la durabilidad, fiabilidad y escalado automático hacen de S3 uno de los componentes obligatorios a la hora de configurar plataformas y ahorrar costes.
Si ha generado tanto ruido el #S3pocalypse es precisamente por lo raro e inesperado del problema y más extraño aún sería que vuelva a ocurrir.
De todas formas, debemos tener algo claro: la responsabilidad en AWS es compartida. Ellos proveen las piezas, pero tú montas la plataforma. Y de ti depende habilitar los mecanismos suficientes para eliminar los posibles SPOF, hay mecanismos suficientes para garantizar plataformas tolerantes a fallos:
- Genera plantillas de Cloudformation de tus plataformas para poder levantarlas en otras regiones.
- Genera plataformas de DR en regiones distintas a la tuya.
- Crea entradas DNS en Route53 que chequeen la disponibilidad de las plataformas.
- Etc.
Como resumen me gustaría resaltar que: gastar en plataformas redundadas nunca es un gasto, es una inversión que siempre deberíamos tener en cuenta. Si tenéis dudas sobre cómo hacerlo no dudéis en contactarnos.
Por cierto, Netflix siguió funcionando. :)
Si te ha gustado este post, ¡síguenos en Twitter!