
Acelerando los desarrollos con contenedores: Publicar la documentación de SchemaSpy
Publicado por Víctor Madrid el
En este artículo vamos a darle una vuelta más al hecho de poder disponer de la documentación visual de la base de datos con SchemaSpy. Para ello, aplicando unos conocimientos mínimos de arquitectura, del uso de contenedores y con un poco de maña vamos a conseguir implementar un componente software que realice un análisis de base de datos en el momento que se le pida y que publique los resultados vía web.

En el anterior artículo generábamos la petición de análisis de la base de datos bajo demanda, teniendo un entorno previo de dependencias instalado para su correcto funcionamiento y obteníamos los resultados en formato HTML los cuales dejábamos bien colocaditos en un directorio.
Este artículo está dividido en 4 partes:
- 1. Introducción
- 2. Stack Tecnológico
- 3. Ejemplos de Uso
- 4. Conclusiones
1. Introducción
En este apartado se tratarán los siguiente puntos :
- 1.1. Introducción al uso de contenedores como aceleradores del desarrollo
- 1.2. ¿Qué necesidades tenemos para "Publicar la documentación de SchemaSpy" con contenedores?
1.1. Introducción al uso de contenedores como aceleradores del desarrollo
Para centralizar esta información en un único punto y así poder facilitar su consulta se ha diseñado un artículo específico
1.2. ¿Qué necesidades tenemos para "Publicar la documentación de SchemaSpy" con contenedores?
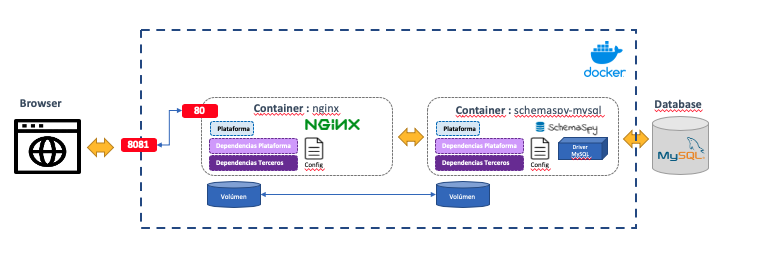
En primer lugar, necesitamos que el propio análisis que antes ejecutábamos en nuestra máquina se ejecute dentro de un contenedor, por lo que tendremos que controlar la plataforma utilizada, las dependencias requeridas, los permisos, ubicaciones de los elementos, configuración específica de Schemaspy etc. Para ello, definiremos un contenedor que facilite todo esto.
Si todo fuera bien durante la ejecución del análisis los resultados serían persistidos dentro del contenedor de forma que inicialmente nadie podría acceder a ellos salvo desde dentro del contenedor, para solucionar esto aprovecharemos el concepto de "montar volúmenes" que es un mecanismo de persistencia de los contenedores permitiendo que los contenedores necesarios puedan acceder a dicha información.
Por último, necesitaremos publicar este contenido al cual trataremos como contenido estático debido a su naturaleza, para ello utilizaremos alguno de los servidores web / proxy inversos que existen como pueden ser Apache o Nginx
Todo esto se implementará de forma que :
- Utilice contenedores y defina un entorno inmutable
- Utilice productos de fuentes oficiales
- Se pueda utilizar en cualquier entorno, es decir, este orientado a uso sobre todo en Producción
- Realice un análisis con cada arranque realizado
- Disponer de un único punto de consulta (similar al uso de Sonarqube) para todo el equipo, área o compañía
Diagrama de propuesta de solución
2. Stack Tecnológico
Este es stack tecnológico elegido para implementar la funcionalidad ""Publicar la documentación de SchemaSpy"
- Docker - Tecnología de Contenedores/Containers
- Docker Hub - Repositorio de Docker Publico donde se ubican las imágenes oficiales
- SchemaSpy - Utilidad de documentación de la base de datos (Versión 6.1.0)
- MySQL - Base de Datos relacional (Version 5.7)
- Nginx - Servidor Web / Proxy Inverso
3. Ejemplos de Uso
Para facilitar el desarrollo del ejemplo, hemos dejado los resucrsos necesarios en un repositorio. En estos ejemplos se implementará el modo de uso : container
¿Qué es el modo de uso "container"?
Ejecuta Schemaspy dentro de un contenedor como una librería Java en base a la configuración de un fichero, generando los resultados HTML en un directorio y exponiendo dichos resultados mediante el uso de Nginx
IMPORTANTE : En este caso Schemaspy tendrá las dependencias instaladas en el container (Graphviz)
En este caso también se enseñarán 2 formas de usarlo pero basados en la incorporación de forma interna (caso interno) o externa (caso externo) de la base de datos.
Preparación del entorno para el caso externo
Para ayudar en la realización del ejemplo del caso externo se ha definido un contenedor Docker de infraestructura para base de datos que montan estructura y contenido de los datos al arrancarlo hemos dejado un dockerfile con la infraestructura en MySQL 5.7
IMPORTANTE: Tiene el detalle de su implementación y uso en su fichero README
Si no te apetece utilizarlo también puedes utilizar tu propia instalación de base de datos on-premise o cloud, esto únicamente implicará cambios en el fichero de configuración utilizado para Schemaspy
Ejecución de los ejemplos
Para facilitar los ejemplos se han definidos dos proyectos de Schemaspy configurados de forma particular para funcionar con la base de datos MySQL utilizada en el apartado "Preparación del entorno" para el caso externo o bien la incorpora por defecto para el caso interno
IMPORTANTE: Cada uno tiene el detalle de su implementación y uso en su fichero README
Ambos casos serán una evolución del modo "Standalone" por lo que se usarán las mismas librerías
Container Schemaspy Internal para MySQL 5.7
La descripción del contenedor de ejecución proporciona la definiciónn de la infraestructura de base de datos, que es levantada junto al contenedor de Schemaspy.
Este enfoque se puede utilizar para entornos local o de desarrollo, donde se quieren hacer pruebas previas y donde en muchos casos la base de datos tiene un juego de datos preparados para testing.
Este proyecto consta de los siguientes elementos:
- Contenedor de Schemaspy
- Proporciona las dependencias requeridas por Schemaspy para su funcionamiento (versión java, graphviz, fuentes, etc.)
- Proporciona las dependencias requeridas para el resto de los elementos (instalar curl, unzip, etc.)
- Proporciona de forma automática la librería de Schemaspy en la versión definida
- Proporciona de forma automática el conector / driver compatible con la base de datos a utilizar
- Define el fichero de configuración que contiene los elementos de conexión a la base de datos a utilizar
- Proporciona el mecanismo de ejecución de Schemaspy
- Contenedor de Nginx
- Proporciona la configuración para publicar la información
- Contenedor de Mysql
- Proporciona la instalación de la base de datos en la versión establecida
- Proporciona un script de carga inicial de estructura y datos
- Proporciona la configuración para su uso (usuarios, password, etc)
Ejemplo de fichero "docker-compose.yaml" para el caso interno
version: '3.7'
services:
mysql-test:
build: ./mysql-5.7
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: acme
MYSQL_USER: test
MYSQL_PASSWORD: test
volumes:
- ./mysql-5.7/config/my.cnf:/etc/mysql/conf.d/my.cnf
- ./mysql-5.7/sql-scripts:/docker-entrypoint-initdb.d
ports:
- 3306:3306
schemaspy-mysql:
build: ./schemaspy-mysql
volumes:
- ./schemaspy-mysql/output:/app/output/
- ./schemaspy-mysql/config/schemaspy.properties:/app/config/schemaspy.properties
command: ["-configFile", "/config/schemaspy.properties"]
network_mode: host
nginx:
build: ./nginx
ports:
- "8081:80"
volumes:
- ./schemaspy-mysql/output:/usr/share/nginx/html:ro
Container Schemaspy External para MySQL 5.7
En este caso la definición no incorpora la infraestructura de base de datos, sino que simplemente se configura una conexión a una base de datos que persiste fuera del ámbito en el que estamos trabajando. Este caso sería lo más parecido a lo que utilizaríamos en un caso real de uso.
Nota : Sería la implementación del "Diagrama de propuesta de solución" planteado en el apartado 1
Este proyecto consta de los siguientes elementos:
- Contenedor de Schemaspy
- Proporciona las dependencias requeridas por Schemaspy para su funcionamiento (versión java, graphviz, fuentes, etc.)
- Proporciona las dependencias requeridas para el resto de los elementos (instalar curl, unzip, etc.)
- Proporciona de forma automática la librería de Schemaspy en la versión definida
- Proporciona de forma automática el conector / driver compatible con la base de datos a utilizar
- Define el fichero de configuración que contiene los elementos de conexión a la base de datos a utilizar
- Proporciona el mecanismo de ejecución de Schemaspy
- Contenedor de Nginx
- Proporciona la configuración para publicar la información
Ejemplo de fichero "docker-compose.yaml" para el caso externo
version: '3.7'
services:
schemaspy-mysql:
build: ./schemaspy-mysql
volumes:
- ./schemaspy-mysql/output:/app/output/
- ./schemaspy-mysql/config/schemaspy.properties:/app/config/schemaspy.properties
command: ["-configFile", "/config/schemaspy.properties"]
network_mode: host
nginx:
build: ./nginx
ports:
- "8081:80"
volumes:
- ./schemaspy-mysql/output:/usr/share/nginx/html:ro
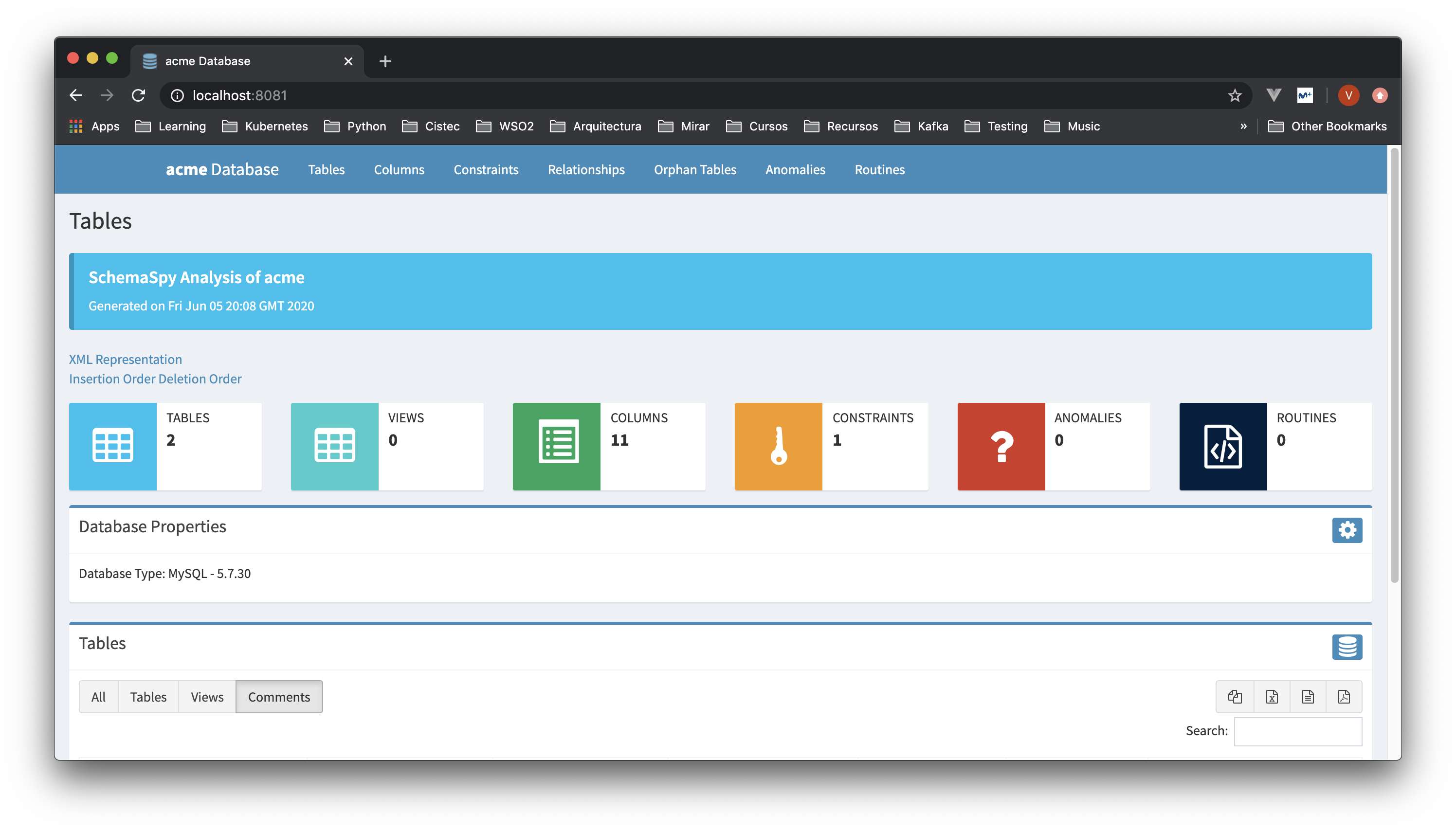
Verificar resultados
Tras la ejecución de lo anterior y si todo hay ido bien se generarán los resultados del análisis en el directorio indicado, estos serán publicados por Nginx momento en el cual podremos acceder y visualizar desde un navegador
4. Conclusiones
Este articulo avanza un paso más en el diseño con respecto al primer artículo, sin que por ello cambien las conclusiones que ya os expuse.
El objetivo ha sido tener un componente "listo" para su uso, tengo que decir, que dependiendo de las circunstancias de cada proyecto habrá que añadir unos cuantos requerimientos de seguridad y de otros tipos, como por ejemplo :
- Disponer de las imágenes en algún registro de contenedores con compatibilidad de Docker
- Diseñar su intervención dentro de una ejecución de un pipeline CI
- Determinar la forma de uso on-premise o bien usando servicios de Cloud específicos
- Definir securización de acceso a esos ficheros de configuración con datos de producción
- Definir securización de gestión de esos contenedores
- Definir securización de acceso por HTTP al servidor Nginx
- ...
Por eso esto ya queda dentro de las particularidades de cada entorno empresarial o de cada proyecto
En mi caso, creo que esta pieza debería de tener el mismo valor a Jenkins o Sonarqube a la hora de utilizarse en los proyectos. Y da igual si se utiliza Schemaspy u otra alternativa ... lo importante es utilizarlo.
Ya me diréis si os hace un poquito más fácil el trabajo :-)