
Captura de datos mediante Debezium y Apache Flink
Publicado por javier sanz el
Arquitectura de SolucionesDebeziumApache FlinkApacke KafkaCDC
las facilidades del procesamiento relativo a captura de datos utilizando Debezium y Apache Flink, sus principales características y mostrarlo como alternativa a otras opciones como Kafka CDC, etc., sin entrar en la comparativa con los mismos.

Antecedentes.
La necesidad de realizar acciones cuando ocurren determinados cambios, actualizaciones de datos en distintas fuentes llevó la formalización del patrón denominado CDC (Change Data Capture), que define soluciones de diseño en las gestiones de eventos que producen cambios y por tanto, tratar los mismos para cumplir con los requerimientos que se planteen.
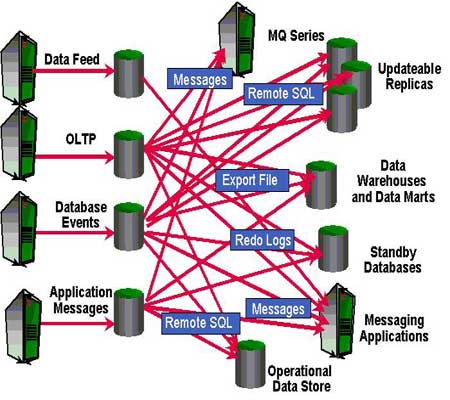
En el entorno de bases de datos, los patrones de CDC definen cómo actuar cuando se ejecutan cambios sobre los datos y cómo propagar éstos a los destinos asignados.
Estas necesidades se planteaban en múltiples escenarios, desde procesamiento en entornos DataWarehouse a entornos de bases de datos con necesidades de sincronización en múltiples destinos (¿quién recuerda las 2PC?), de tal forma que la resolución de estas problemáticas ha sido un proceso que ha evolucionado adaptándose a las facilidades técnicas como a los nuevos modelos de procesamiento sobre eventos (CDC vs CQRS).
Procesamiento estilo "Captura de datos".
Para mostrar la evolución del CDC podemos seguir las acciones que Oracle, como uno de los representantes de los mayores vendedores de bases de datos, fue construyendo para cubrir las necesidades de sus clientes en este nuevo modelo de procesamiento y que, con ello, claro está, compraran sus bases de datos (y les funcionó).
Si bien, los planteamientos generales que se podían aplicar eran básicamente definir y ejecutar procedimientos almacenados (PL-SQL) asociados a triggers o vistas materializadas, ambas tareas eran excesivamente complejas, costosas de desarrollar y mantener, por lo que quedaba patente que la necesidad de un "framework" que atendiera a estas problemáticas iba a tener su sitio en el mercado de soluciones técnicas a ofrecer a los clientes.
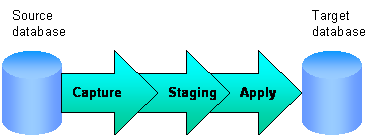
En ese sentido, y con la aparición y uso (casi obligado) de sistemas de mensajería (pub-sub/queue), los llamados middlewares, se plantearon dos opciones generales para resolver estos problemas de captura de datos:
- Aplicar un framework centrado en los procesos de captura de datos alineado con el lenguaje de programación (usar una librería el fabricante de la base de datos y la configuración correspondiente) que atendiera al proceso como tal de detección y propagación de los datos.
- Un mecanismo más genérico (y también atado a la base de datos) que transformara las capacidades de gestión del cambio/evento adaptado a las soluciones de mensajería (en búsqueda de mayor procesamiento).
La aplicación de abstracciones Java-JDBC en CDC seguían siendo complicadas de llevar a cabo (no formaban parte de la especificación), y por ello, siguiendo con Oracle, éstos cubrieron las necesidades de mercado en las dos vertientes:
- Oracle Streams (con sus evoluciones, adaptaciones alias XStreams)
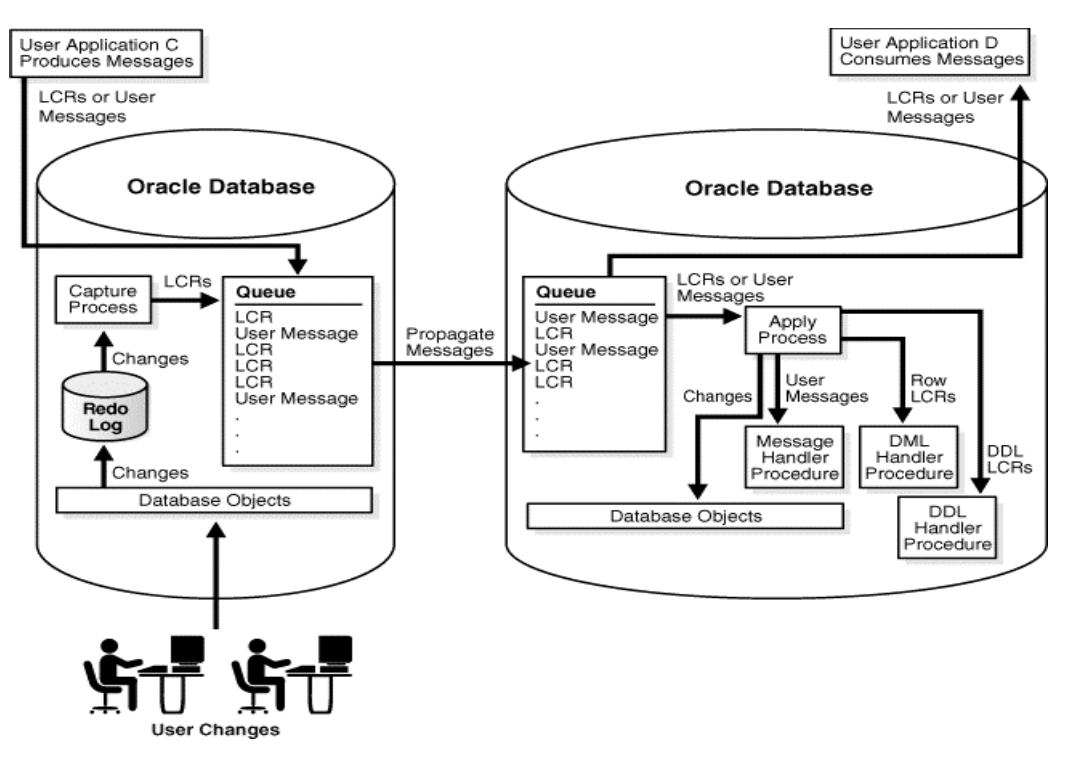
- Oracle Change Data Capture framework
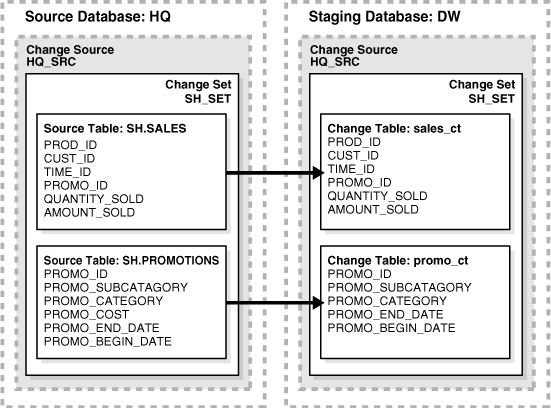
Y con estos escenarios, Oracle ofrecía su -maravilloso- Oracle GoldenGate que era una herramienta que permitía "replicar" (que más bien se hubiera que haber utilizado el término, no comercial claro, "alinear") distintas bases de datos Oracle para verse como sincronizadas, replicadas y su uso como posibilidades de backup, proxy de escalado en procesos de consultas, gestión de instancias activo-pasivo, etc., quién lo iba a decir, se le intentaba dar más usos de los determinados e incluso de los esperados.
Debezium.

Como se puede observar, en función del fabricante, base de datos, lenguaje de programación, transformaciones a realizar, volumetrías, en resumen, orígenes-destinos, el enfoque de la solución estaba muy atado a soluciones poco genéricas.
La necesidad de ofrecer una solución estilo navaja suiza que cubriera las operativas de captura y procesamiento del dato con los mínimos ajustes en función de origen y destino ha sido el proceso de construcción y evolución en las soluciones CDC.
Evidentemente, CDC ha ido conformado una serie de propiedades que se repetían a lo largo del tiempo:
- Que el procesamiento en la captura de los eventos de cambio fuera lo menos intrusivo en el sistema origen.
- Disponer de la mayor variedad de productos sobre los que poder actuar (Oracle, Sybase, Mysql, Postgres, AWS Kinesis...) y de forma lo más genérica posible.
- Con valores de acción, actuación, detección frente al cambio generado, lo más próximo a su ejecución ... o no. (Permítanme no entrar en más detalles en lo referente a este -asuntillo-).
- Disponer de gestiones de procesamiento que se pueden alinear a necesidades como volumen de transferencia de datos/transformaciones o por necesidades de tiempo respuesta.
La necesidad de una respuesta que fuera incorporando soluciones a todas estas necesidades fue desarrollada desde RedHat, se llama Debezium y afortunadamente, acabó convirtiéndolo en un proyecto OpenSource.
 debezium
debeziumMediante Debezium disponemos de una solución que nos permite resolver los procesos de captura de datos (centrados en la gestión de los logs de las bases de datos y evitarnos el horror de saber que ocurre a esos niveles) operando bajo el concepto del uso de un conector, como elemento que se encarga de realizar todas las gestiones sobre una fuente de datos generando los eventos que vamos a procesar y dar respuesta las necesidades de negocio sobre la transformación más que sobre cómo tratar todo este movimiento de eventos.
En la web de Debezium se pueden consultar los distintos tipos de conectores que se pueden aplicar, existen multitud de ejemplos, es una comunidad bastante activa y el soporte es más que amplio.
El modelo de referencia de captura de datos usando Apache Kafka
Dado que estamos procesando eventos -de cambio-, la tendencia técnica actual es apoyar la solución en tecnología de procesamiento de eventos basado en la conceptualización del concepto de -stream- (término, creo, se definió en Unix System V para definir el modelo de programación entre los drivers de los dispositivos y los programas, y que en la bibliografía técnica se interpretaba con expresiones del estilo... 'chorizo de bits que circulan de un sitio a otro de forma continua...', con el resumen ... 'en Unix todo son ficheros').
Sin entrar ya en definiciones más formales, y poniendo el foco en su aplicación en entornos BigData, la gestión de eventos en streaming es una solución que permite una paralelización del procesamiento relativamente sencilla, organizada, escalable, controlada y mantenible.
En esa línea, igual que he puesto a Oracle como ejemplo, aquí aparece la empresa Confluent, que como propietaria final del esfuerzo de la comunidad OpenSouce que participó en un grado considerable en que Apache Kafka se conformara como lo es actualmente y las subsiguientes añadiduras que lo han ido reforzando, sea el referente en la aplicación de su Kafka Connect con Debezium para resolver los procesos de captura del dato aplicando posteriormente Apache Kafka (middleware).
Por ellos se va a describir brevemente un flujo CDC involucrando a la base de datos Postgres y Apache Kafka:
Postgres-> evt -> Debezium -> evt -> Kafka [Topic]
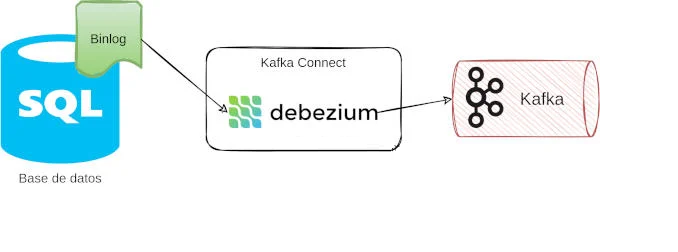
Se genera la infraestructura apoyándose en un docker-compose que contendrá:
- Postgres
- debezium-conector
- Kafka
Se arranca un entorno simple dockerizado:
$docker-compose -f df-kafka.yaml up
version: '3.1'
services:
postgres:
image: debezium/postgres
environment:
POSTGRES_PASSWORD: qwerty
POSTGRES_USER: appuser
volumes:
- ./postgres:/data/postgres
ports:
- 6532:6532
zookeeper:
image: confluentinc/cp-zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
kafka:
image: confluentinc/cp-kafka
depends_on:
- zookeeper
- postgres
ports:
- "9092:9092"
environment:
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_LOG_CLEANER_DELETE_RETENTION_MS: 5000
KAFKA_BROKER_ID: 1
KAFKA_MIN_INSYNC_REPLICAS: 1
connector:
image: debezium/connect:latest
ports:
- "8083:8083"
environment:
GROUP_ID: 1
CONFIG_STORAGE_TOPIC: my_connect_configs
OFFSET_STORAGE_TOPIC: my_connect_offsets
BOOTSTRAP_SERVERS: kafka:9092
depends_on:
- zookeeper
- postgres
- kafkaUna vez arrancado, tendrá este detalle:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d79a79d5777c debezium/connect:latest "/docker-entrypoint.…" 41 minutes ago Up 41 minutes 0.0.0.0:8083->8083/tcp, :::8083->8083/tcp, 9092/tcp cdc_connector_1
a4be566799b6 confluentinc/cp-kafka "/etc/confluent/dock…" 41 minutes ago Up 41 minutes 0.0.0.0:9092->9092/tcp, :::9092->9092/tcp cdc_kafka_1
72cc6d8bae2f confluentinc/cp-zookeeper "/etc/confluent/dock…" 41 minutes ago Up 41 minutes 2888/tcp, 0.0.0.0:2181->2181/tcp, :::2181->2181/tcp, 3888/tcp cdc_zookeeper_1
2df50e6be5df debezium/postgres "docker-entrypoint.s…" 41 minutes ago Up 41 minutes 5432/tcp, 0.0.0.0:6532->6532/tcp, :::6532->6532/tcp cdc_postgres_1Se arrancan los distintos elementos:
- Postgres, se conecta al conector y se relaciona con base de datos.
docker-compose exec postgres psql -h localhost -U appuser
- o -
docker exec -it <postgres_container_id> bash
psql -h localhost -p 5432 -U appuser
$ CREATE DATABASE payment;
$ \c payment
$ CREATE TABLE transaction(id SERIAL PRIMARY KEY, amount int, customerId varchar(36));Se generan eventos:
$ insert into transaction(id, amount,customerId) values(1885, 87,'37b920fd-ecdd-7172-693a-d7be6db9792c');
$ update transaction set amount=77 where id=8852. Se define la relación con el Kafka.
Se envía la petición al conecto Debezium para que determine que datos del Postgres hay que tratar, se configura en que broker y en que topic de Kafka se dejan los eventos de CDC.
$ curl -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d '
{
"name": "payment-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "appuser",
"database.password": "qwerty",
"database.dbname" : "payment",
"database.server.name": "dbserver1",
"database.whitelist": "payment",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "schema-changes.payment",
"topic.prefix": "payment"
}
}'Se comprueba que el conector Debezium esta ok,
$curl localhost:8083/connectors/payment-connector/status |jq
{"name":"payment-connector","connector":{"state":"RUNNING","worker_id":"172.21.0.5:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"172.21.0.5:8083"}],"type":"source"}
Comprobamos si se ha realizado en enlace en Kafka y el topic:
$docker exec -it <kafka_container_id> bash
$ kafka-topics --list --bootstrap-server=kafka:9092
__consumer_offsets
connect-status
my_connect_configs
my_connect_offsets
payment.public.transaction3. Se lanza el consumidor para recibir los eventos de CDC respecto a las operaciones que se hayan en el Postgres-container-id en la tabla correspondiente:
$ kafka-console-consumer --bootstrap-server kafka:9092 --from-beginning --topic payment.public.transaction --property print.key=true --property key.separator="-"
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"default":0,"field":"id"}],"optional":false,"name":"payment.public.transaction.Key"},"payload":{"id":51}}-{"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"default":0,"field":"id"},{"type":"int32","optional":true,"field":"amount"},{"type":"string","optional":true,"field":"customerid"}],"optional":true,"name":"payment.public.transaction.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"default":0,"field":"id"},{"type":"int32","optional":true,"field":"amount"},{"type":"string","optional":true,"field":"customerid"}],"optional":true,"name":"payment.public.transaction.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false,incremental"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":false,"field":"schema"},{"type":"string","optional":false,"field":"table"},{"type":"int64","optional":true,"field":"txId"},{"type":"int64","optional":true,"field":"lsn"},{"type":"int64","optional":true,"field":"xmin"}],"optional":false,"name":"io.debezium.connector.postgresql.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"name":"event.block","version":1,"field":"transaction"}],"optional":false,"name":"payment.public.transaction.Envelope","version":1},"payload":{"before":null,"after":{"id":51,"amount":12,"customerid":"37b920fd-ecdd-7172-693a-d7be6db9792c"},"source":{"version":"2.0.1.Final","connector":"postgresql","name":"payment","ts_ms":1673952547549,"snapshot":"last","db":"payment","sequence":"[null,\"23728576\"]","schema":"public","table":"transaction","txId":556,"lsn":23728576,"xmin":null},"op":"r","ts_ms":1673952547649,"transaction":null}}
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"default":0,"field":"id"}],"optional":false,"name":"payment.public.transaction.Key"},"payload":{"id":51}}-{"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"default":0,"field":"id"},{"type":"int32","optional":true,"field":"amount"},{"type":"string","optional":true,"field":"customerid"}],"optional":true,"name":"payment.public.transaction.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"default":0,"field":"id"},{"type":"int32","optional":true,"field":"amount"},{"type":"string","optional":true,"field":"customerid"}],"optional":true,"name":"payment.public.transaction.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false,incremental"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":false,"field":"schema"},{"type":"string","optional":false,"field":"table"},{"type":"int64","optional":true,"field":"txId"},{"type":"int64","optional":true,"field":"lsn"},{"type":"int64","optional":true,"field":"xmin"}],"optional":false,"name":"io.debezium.connector.postgresql.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"name":"event.block","version":1,"field":"transaction"}],"optional":false,"name":"payment.public.transaction.Envelope","version":1},"payload":{"before":null,"after":{"id":51,"amount":999,"customerid":"37b920fd-ecdd-7172-693a-d7be6db9792c"},"source":{"version":"2.0.1.Final","connector":"postgresql","name":"payment","ts_ms":1673952653066,"snapshot":"false","db":"payment","sequence":"[null,\"23728768\"]","schema":"public","table":"transaction","txId":557,"lsn":23728768,"xmin":null},"op":"u","ts_ms":1673952653291,"transaction":null}}Apache Flink.

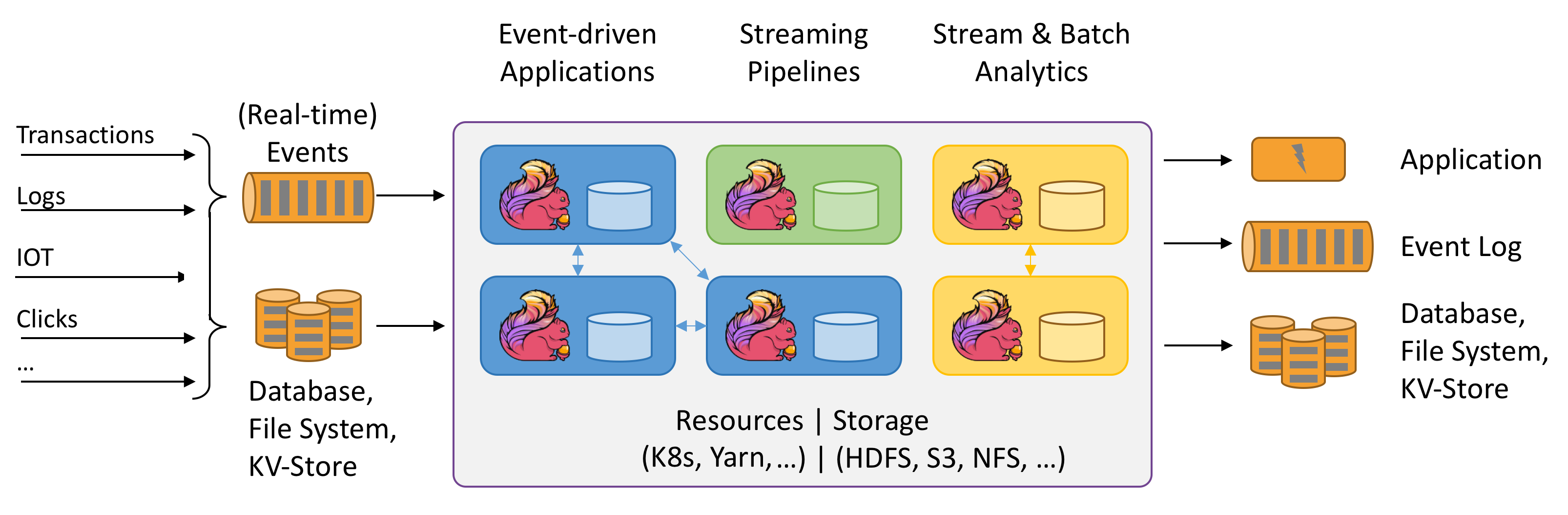
Anteriormente se ha descrito un flujo con Apache Kafka, donde se puede apreciar que hay un cierto nivel de detalle técnico sobre el que podríamos y queremos tener más abstracción.
Por ello, vamos a presentar Apache Flink en relación a una de sus capacidades de procesamiento de forma más inmediata en el flujo de captura de datos en tanto y cuando queremos procesar y utilizar streams, pero operar sobre estructuras de datos más tradicionales, tablas de SQL de toda la vida.
¿Quién se va a encargar de mapear streams y tablas de bases de datos sin que participemos en ese proceso?. Pues Apache Flink y de hecho, no querríamos ni saber que existen los streams ni que tengo que usarlos.
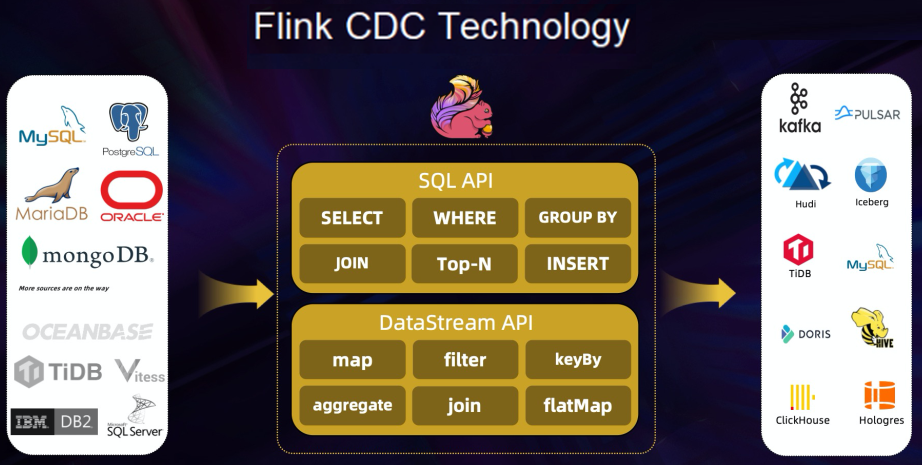
Además, la versatilidad que podemos tener con Apache Flink en estos escenarios es que también disponemos de -conectores- por los cuales Flink se va a encargar de enviar los datos capturados al -sink- asociado, que puede ser un Apache Kafka, como un Elastic, etc.

Breve introducción al CDC con Apache Flink.
Los escenarios a resolver en procesos CDC siguen pudiéndose agrupar en tres grandes áreas :
- Procesos Data Distribution: la solución pasa por distribuir las fuentes de datos entre distintos/múltiples destinos donde se procesan. Aplicable en plataformas orientas a procesamiento con microservicios, entornos donde se quiere desacoplar los procesos de negocio, etc.
- Acciones Data Integration: Se busca integrar las distintas fuentes de datos (descentralizadas y heterogeneas) en un data warehouse -operativo- para eliminar en la medida de los posible los data silos y ofrecer una mejora de los análisis de datos.
- Tareas de Data Migration: Cubrir necesidades de DBS y disaster recovery.
Para ellos, Apache Flink CDC se basa en poder ejecutar procesamiento de datos (full-data e incrementales) con propiedades de sincronización y consistencia (amigos de Apache Spark, cuénteme, cuénteme sobre esta conjunción) en tiempo real.
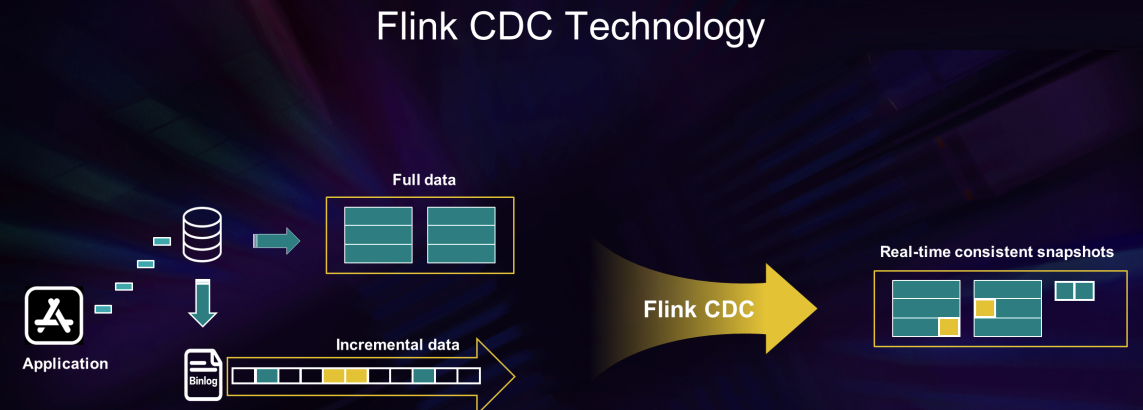
Ya más técnicamente, Apache Flink tiene estas características (en cuyo detalle se entrará en próximos artículos).

Para los procesos Data Distribution,

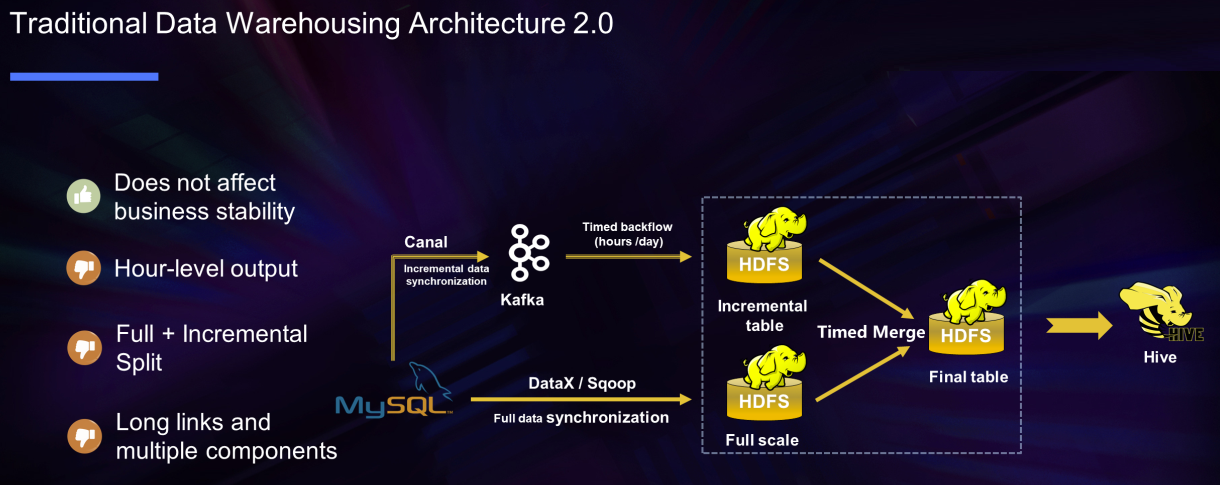
En el Data Integration, se da respuesta, por ejemplo, a la problemática en el uso de soluciones Data Warehouse y sus problemas recurrentes:

También hay que reconocer que se ha mejorado mucho en una solución operativa, pero ciertamente compleja:
Y en Data Migration, con enfoque de subconjunto de acciones Data Lake:
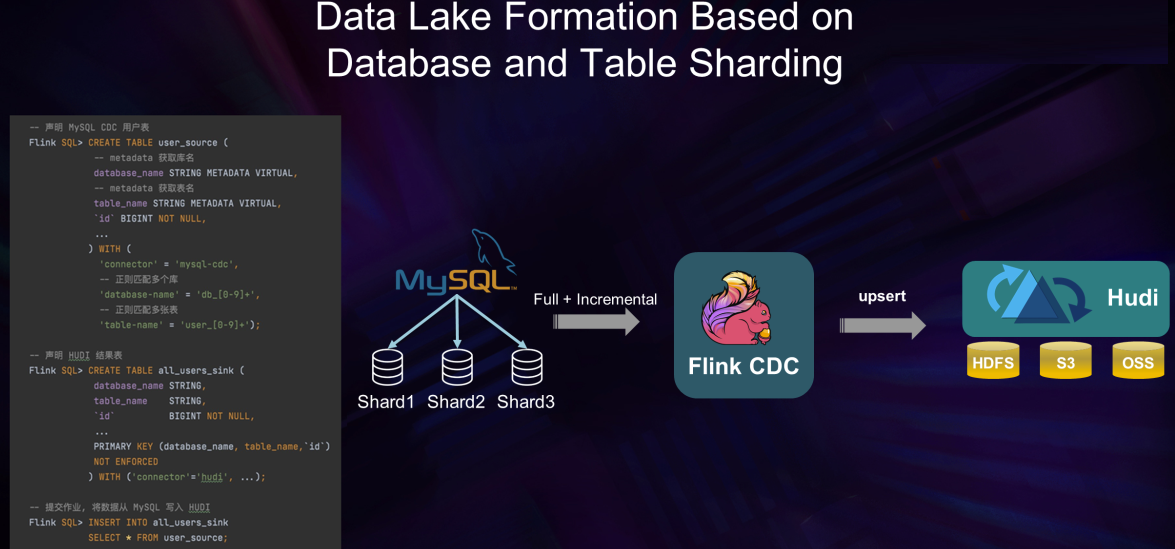
CDC Multibase de datos, Flink, ElasticSearch.
Volviendo a la parte práctica, se va a describir brevemente un flujo CDC involucrando las bases de datos Postgres y Mysql, procesando el flujo con Apache Flink y volcando la resultante en ElastiSearch, siguiendo la misma operación que en la anterior muestra.
[Pstgres, Mysql] -> evt -> Debezium -> Apache Flink -> evt -> Elastic
Se genera la infraestructura apoyándose en un docker-compose que contendrá:
- Postgres, Mysql
- debezium-conector
- flink local jar, sql-client jars adhoc
- Elastic/Kibana
Una vez arrancado el entorno:
docker-compose up
version: '2.1'
services:
postgres:
image: debezium/example-postgres:1.1
ports:
- "5432:5432"
environment:
- POSTGRES_DB=postgres
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
mysql:
image: debezium/example-mysql:1.1
ports:
- "3306:3306"
environment:
- MYSQL_ROOT_PASSWORD=123456
- MYSQL_USER=mysqluser
- MYSQL_PASSWORD=mysqlpw
- TZ=Europe/Madrid
elasticsearch:
image: elastic/elasticsearch:7.6.0
environment:
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.type=single-node
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
kibana:
image: elastic/kibana:7.6.0
ports:
- "5601:5601"Una vez arrancado, tendrá este detalle:
[vagrant@fedora ~]$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b01c830c1c70 debezium/example-mysql:1.1 "docker-entrypoint.s…" 23 hours ago Up 19 seconds 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp, 33060/tcp cdc-docker-n-sources_mysql_1
b76fd52044ad elastic/elasticsearch:7.6.0 "/usr/local/bin/dock…" 23 hours ago Up 19 seconds 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp cdc-docker-n-sources_elasticsearch_1
2cd3b6dd4d8e debezium/example-postgres:1.1 "docker-entrypoint.s…" 23 hours ago Up 19 seconds 0.0.0.0:5432->5432/tcp, :::5432->5432/tcp cdc-docker-n-sources_postgres_1
de472d461bac elastic/kibana:7.6.0 "/usr/local/bin/dumb…" 23 hours ago Up 19 seconds 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp cdc-docker-n-sources_kibana_1
[vagrant@fedora ~]$Para no complicar la demostración (gestión de recursos en demo local), se instala Apache Flink 1.16 en local, https://archive.apache.org/dist/flink/flink-1.16.0/flink-1.16.0-bin-scala_2.12.tgz y se copia en /lib los jar adhoc de los sources y sink adecuados.
[vagrant@fedora lib]$ ls -lrt
total 533012
-rw-r--r-- 1 vagrant vagrant 28428885 Oct 20 04:55 flink-sql-connector-elasticsearch7-1.16.0.jar
-rw-r--r-- 1 vagrant vagrant 22968127 Nov 9 16:11 flink-sql-connector-mysql-cdc-2.3.0.jar
-rw-r--r-- 1 vagrant vagrant 18383389 Nov 9 16:14 flink-sql-connector-postgres-cdc-2.3.0.jar
[vagrant@fedora lib]$ATENCIÓN:
Importante revisar versiones de JARs, así como las referencias a snapshosts que pudieran existir. Respecto a la JDK, revisar:
- Inicialmente vamos a utilizar JDK 8.
- Se recomienda JDK 11, pero ... hay que revisar y actualizar la configuración en algunos java lang accessilegal.
- Se puede probar con JDK 17 .. hay varios temas de jvm a tener en consideración .. pero nada que impida la ejecución.
En bin/config.sh se recomienda introducir el fix:
DEFAULT_ENV_JAVA_OPTS_JM=" --add-opens java.base/java.lang=ALL-UNNAMED --add-exports=java.base/sun.net.util=ALL-UNNAMED" # Optional JVM args (JobManager)
DEFAULT_ENV_JAVA_OPTS_TM=" --add-opens java.base/java.lang=ALL-UNNAMED --add-exports=java.base/sun.net.util=ALL-UNNAMED" # Optional JVM args (TaskManager)
DEFAULT_ENV_JAVA_OPTS_HS=" --add-opens java.base/java.lang=ALL-UNNAMED --add-exports=java.base/sun.net.util=ALL-UNNAMED" # Optional JVM args (HistoryServer)
DEFAULT_ENV_JAVA_OPTS_CLI=" --add-opens java.base/java.lang=ALL-UNNAMED --add-exports=java.base/sun.net.util=ALL-UNNAMED" # Optional JVM args (Client)
seguira en jdk 11 saliendo un WARN sobre illegal access en java lang annotations que se puede ignorar...
[INFO] Submitting SQL update statement to the cluster...
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.flink.api.java.ClosureCleaner (file:/home/vagrant/cdc-platform/cdc-docker-flink-kafka/flink-1.16.0/lib/flink-dist-1.16.0.jar) to field java.lang.Class.ANNOTATION
WARNING: Please consider reporting this to the maintainers of org.apache.flink.api.java.ClosureCleaner
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future releaseSe arrancan los distintos elementos:
- Postgres, se conecta al conector y a la base de datos:
docker-compose exec postgres psql -h localhost -U appuser
- o -
docker exec -it <postgres_container_id> bash
psql -h localhost -p 5432 -U postgres
-- PG
CREATE TABLE shipments (
shipment_id SERIAL NOT NULL PRIMARY KEY,
order_id SERIAL NOT NULL,
origin VARCHAR(255) NOT NULL,
destination VARCHAR(255) NOT NULL,
is_arrived BOOLEAN NOT NULL
);
ALTER SEQUENCE public.shipments_shipment_id_seq RESTART WITH 1001;
ALTER TABLE public.shipments REPLICA IDENTITY FULL;
INSERT INTO shipments
VALUES (default,10001,'Beijing','Shanghai',false),
(default,10002,'Hangzhou','Shanghai',false),
(default,10003,'Shanghai','Hangzhou',false);2. Mysql, se conecta al conector y creación,
docker-compose exec mysql mysql -uroot -p123456
-- MySQL
CREATE DATABASE mydb;
USE mydb;
CREATE TABLE products (
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
description VARCHAR(512)
);
ALTER TABLE products AUTO_INCREMENT = 101;
INSERT INTO products
VALUES (default,"scooter","Small 2-wheel scooter"),
(default,"car battery","12V car battery"),
(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"),
(default,"hammer","12oz carpenter's hammer"),
(default,"hammer","14oz carpenter's hammer"),
(default,"hammer","16oz carpenter's hammer"),
(default,"rocks","box of assorted rocks"),
(default,"jacket","water resistent black wind breaker"),
(default,"spare tire","24 inch spare tire");
CREATE TABLE orders (
order_id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
order_date DATETIME NOT NULL,
customer_name VARCHAR(255) NOT NULL,
price DECIMAL(10, 5) NOT NULL,
product_id INTEGER NOT NULL,
order_status BOOLEAN NOT NULL -- Whether order has been placed
) AUTO_INCREMENT = 10001;
INSERT INTO orders
VALUES (default, '2020-07-30 10:08:22', 'Jark', 50.50, 102, false),
(default, '2020-07-30 10:11:09', 'Sally', 15.00, 105, false),
(default, '2020-07-30 12:00:30', 'Edward', 25.25, 106, false);3. Arranque de Apache Flink,
[vagrant@fedora bin]$ ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host fedora.
Starting taskexecutor daemon on host fedora.
[vagrant@fedora bin]$Deberíamos observar un dashboard Flink estilo,
4. Lanzamos el mapeo a streams-tablas en Flink mediente el sq-client de Flink, porque efectivamente, se van a transformar los streams en tablas predeterminadas en Flink.
Y en la consola, configuramos los mapeos y el destino Elastic.
-- Flink SQL
Flink SQL> SET execution.checkpointing.interval = 3s;
-- Flink SQL
Flink SQL> CREATE TABLE products (
id INT,
name STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'products'
);
Flink SQL> CREATE TABLE orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'orders'
);
Flink SQL> CREATE TABLE shipments (
shipment_id INT,
order_id INT,
origin STRING,
destination STRING,
is_arrived BOOLEAN,
PRIMARY KEY (shipment_id) NOT ENFORCED
) WITH (
'connector' = 'postgres-cdc',
'hostname' = 'localhost',
'port' = '5432',
'username' = 'postgres',
'password' = 'postgres',
'database-name' = 'postgres',
'schema-name' = 'public',
'table-name' = 'shipments'
);
-- Flink SQL
Flink SQL> CREATE TABLE enriched_orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
product_name STRING,
product_description STRING,
shipment_id INT,
origin STRING,
destination STRING,
is_arrived BOOLEAN,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://localhost:9200',
'index' = 'enriched_orders'
);Con ello, se definen las relaciones que convierten en stream/tabla dinámica (unbounded stream) las tablas de Postgres y MySql en tablas dinámicas Flink para CDC.
Vamos a lanzar la CDC en Flink que carga en Elastic y se procesa dentro de Kibana. Esto genera un job en Flink y no es ni más ni menos que un SQL.
-- Flink SQL
Flink SQL> INSERT INTO enriched_orders
SELECT o.*, p.name, p.description, s.shipment_id, s.origin, s.destination, s.is_arrived
FROM orders AS o
LEFT JOIN products AS p ON o.product_id = p.id
LEFT JOIN shipments AS s ON o.order_id = s.order_id;Comprobando que el jobs Flink generado está correctamente operando:
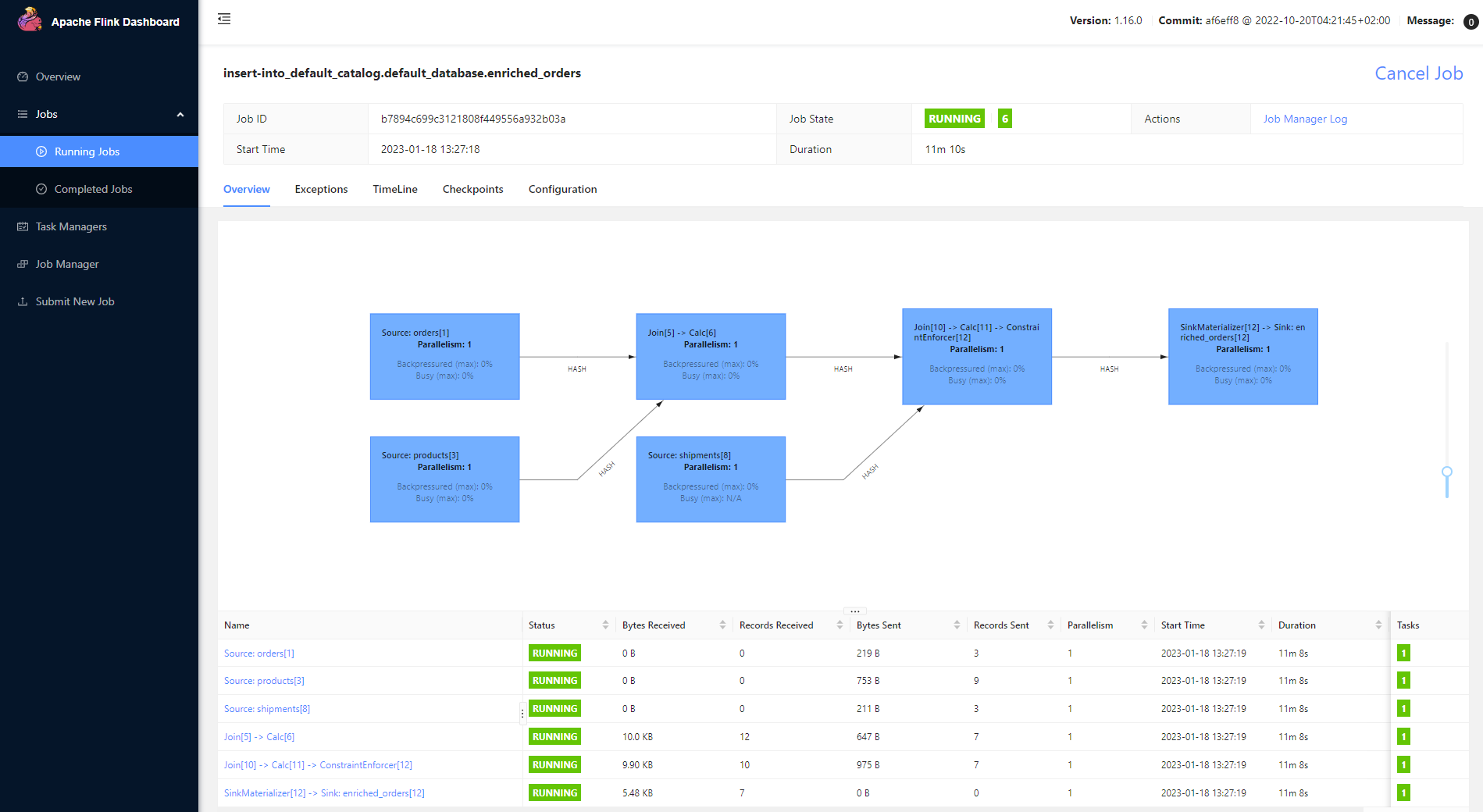
Se añade el índice en Elastic,
http://localhost:5601/app/kibana#/management/kibana/index_pattern
creando index pattern enriched_orders y una vez generado, se lanzar el discover para la carga de datos,
http://localhost:5601/app/kibana#/discover
aplicando el índice enriched orders.
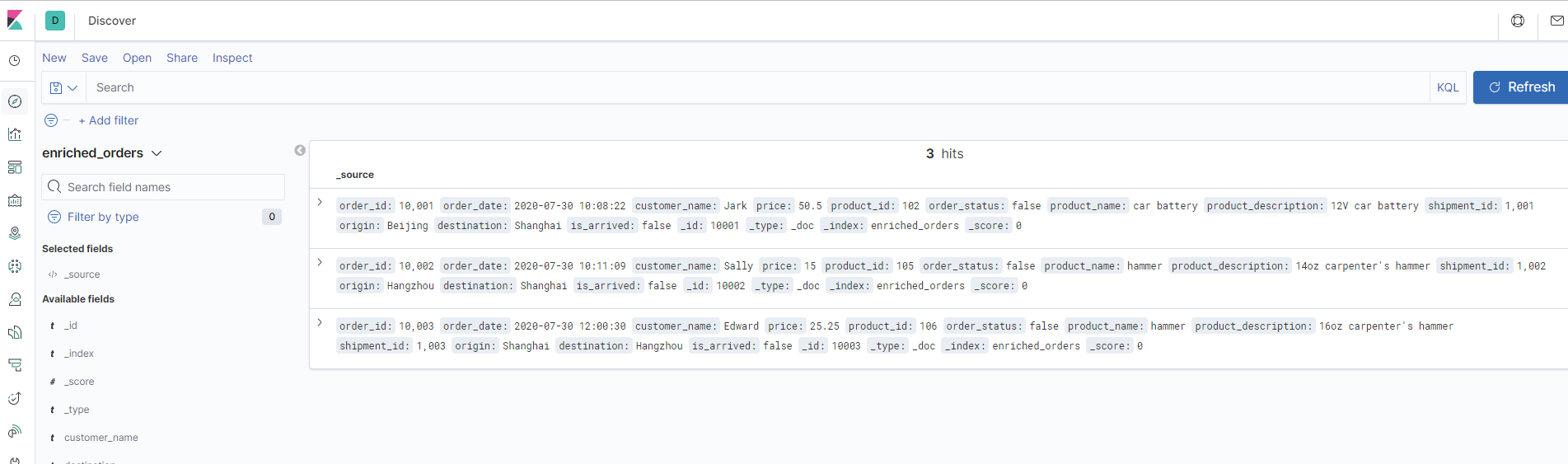
Como se puede observar, el proceso de captura con Flink es menos complejo técnicamente, permite explotar todas las posibilidades de Flink en procesamiento paralelo, lanzamiento de jobs y mapeos adaptados a las mismas fuentes de datos, etc.
CDC Postgres, Apache Flink y Apache Kafka.
Para integrar a los fans de Apache Kafka y sin perder el uso y potencia de Apache Flink, se va a mostrar un flujo de captura con esos elementos.
Como se ha mostrado anteriormente, se genera la infraestructura apoyándose en un docker-compose definido al que añadiremos Apache Kafka, y el total contendrá:
- Docker Postgres [debezium-conector]
- Apache Flink local jar, sql-client jars locales adhoc
- Docker Kafka
Una vez arrancado el entorno:
docker-compose up
version: '2.1'
services:
postgres:
image: debezium/example-postgres:1.1
ports:
- "5432:5432"
environment:
- POSTGRES_DB=postgres
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
zookeeper:
image: confluentinc/cp-zookeeper
ports:
- '2181:2181'
environment:
ZOOKEEPER_CLIENT_PORT: 2181
kafka:
image: confluentinc/cp-kafka
depends_on:
- zookeeper
ports:
- '9092:9092'
environment:
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://kafka:9092'
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_LOG_CLEANER_DELETE_RETENTION_MS: 5000
KAFKA_BROKER_ID: 1
KAFKA_MIN_INSYNC_REPLICAS: 1
Una vez arrancado, tendrá este detalle:
[vagrant@fedora cdc-pg-flink-kafka]$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
38bce557b611 confluentinc/cp-kafka "/etc/confluent/dock…" 46 minutes ago Up 46 minutes 0.0.0.0:9092->9092/tcp, :::9092->9092/tcp cdc-docker-flink-kafka_kafka_1
9370d6116d39 confluentinc/cp-zookeeper "/etc/confluent/dock…" 46 minutes ago Up 46 minutes 2888/tcp, 0.0.0.0:2181->2181/tcp, :::2181->2181/tcp, 3888/tcp cdc-docker-flink-kafka_zookeeper_1
9a3a5a36650c debezium/example-postgres:1.1 "docker-entrypoint.s…" 46 minutes ago Up 46 minutes 0.0.0.0:5432->5432/tcp, :::5432->5432/tcp cdc-docker-flink-kafka_postgres_1
[vagrant@fedora cdc-pg-flink-kafka]$Se arrancan los distintos elementos:
- Postgres, se conecta al conector y a la postgres
docker-compose exec postgres psql -h localhost -U appuser
- o -
docker exec -it <postgres_container_id> bash
psql -h localhost -p 5432 -U postgres
-- PG
CREATE TABLE shipments (
shipment_id SERIAL NOT NULL PRIMARY KEY,
order_id SERIAL NOT NULL,
origin VARCHAR(255) NOT NULL,
destination VARCHAR(255) NOT NULL,
is_arrived BOOLEAN NOT NULL
);
ALTER SEQUENCE public.shipments_shipment_id_seq RESTART WITH 1001;
ALTER TABLE public.shipments REPLICA IDENTITY FULL;
INSERT INTO shipments
VALUES (default,10001,'Beijing','Shanghai',false),
(default,10002,'Hangzhou','Shanghai',false),
(default,10003,'Shanghai','Hangzhou',false);2. Arranque de Apache Flink y desde la consola Flink, definimos el -sink- Kafka.
-- Flink SQL
Flink SQL> SET execution.checkpointing.interval = 3s;
-- Flink SQL
CRATE TABLE shipments (
shipment_id INT,
order_id INT,
origin STRING,
destination STRING,
is_arrived BOOLEAN,
PRIMARY KEY (shipment_id) NOT ENFORCED
) WITH (
'connector' = 'postgres-cdc',
'hostname' = 'localhost',
'port' = '5432',
'username' = 'postgres',
'password' = 'postgres',
'database-name' = 'postgres',
'schema-name' = 'public',
'table-name' = 'shipments'
);
SET execution.result-mode=changelog; -- indicamos que el job requiere de upsert processing
CREATE TABLE kshipments (
shipment_id INT,
order_id INT,
origin STRING,
destination STRING,
is_arrived BOOLEAN,
PRIMARY KEY (shipment_id) NOT ENFORCED
)
WITH (
'connector' = 'upsert-kafka', -- using kafka connector, indicar que el modo envio a topic => upsert
'topic' = 'kshipments', -- kafka topic
'properties.bootstrap.servers' = 'localhost:9092', -- kafka broker address localhost porque el jar esta en local
'key.format' = 'csv',
'value.format' = 'csv'
);
Con ello se definen las relaciones que convierten en stream/tabla dinámica (unbounded stream) las tablas de Postgres en tabla dinámica Flink para CDC y la tabla dinámica del topic Kafka destino. Como se observa, el proceso es básicamente el mismo.
Vamos a lanzar la sql Flink que carga en el topic Kafka. Esto genera un job en Flink.
INSERT INTO kshipments SELECT * FROM shipments;Tenemos Flink Job,
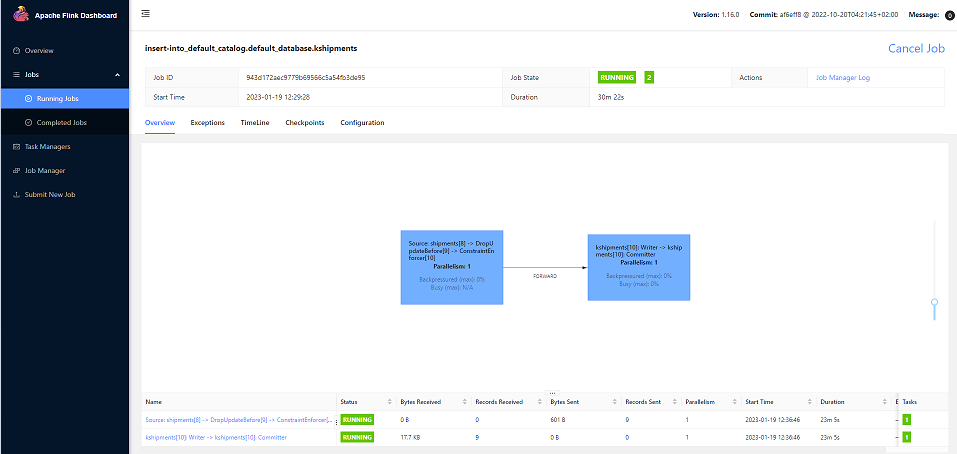
Y veamos que tenemos por el Apache Kafka, que los datos CDC acaban en el topic de Apache Kafka en topic kshipments,
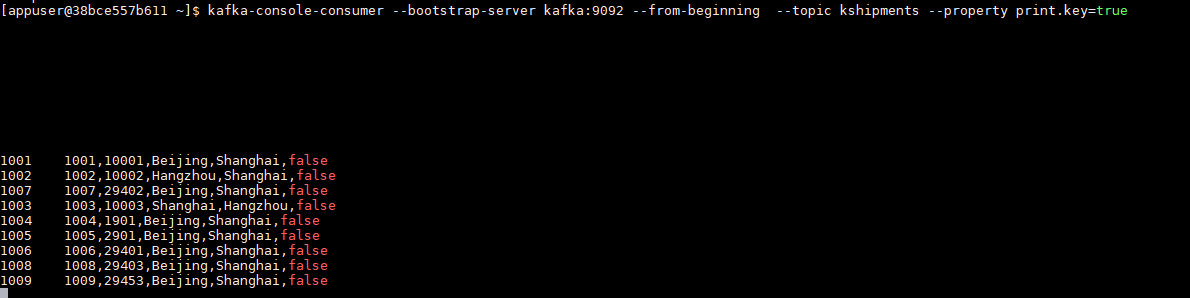
Conclusiones.
Se ha presentado un modelo CDC mediante Debezium y Apache Flink como una alternativa potente, escalable y ampliada, apoyada en streams y procesamiento paralelo, basada en OpenSource que cubrir los escenarios globales -Data- de procesamiento.
Si te ha gustado, ¡síguenos en Twitter para estar al día de próximos posts!