
¿Conoces Neo4j o sabes de qué va?
Publicado por Alfredo Rondón el
En el siguiente artículo se mostrarán las funcionalidades, usos, arquitecturas, de Neo4j para ser aplicado por todos los apasionados del desarrollo de software e implementado de una manera rápida y sencilla.

Siendo esta una de las tecnologías más punteras y competitivas del mercado, usada actualmente por grandes empresas como: Facebook, Instagram, Twitter entre otras, debido a su gran escalabilidad, rapidez, eficiencia, seguridad como base de datos NoSQL entre otras.
¿Qué es Neo4j?

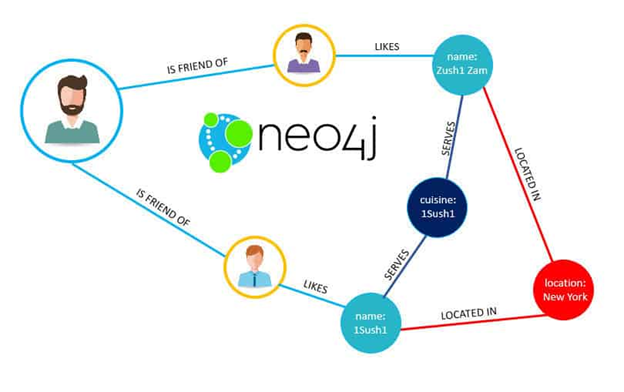
Neo4j es una base de datos orientada a grafos diseñada en Java, basada en una base de datos NoSQL (no relacional), y modelada en nodos vértices y aristas.
Un nodo es la representación atómica de un objeto, el vértice es el inicio de la relación que pueda tener con uno o n nodos y aristas las líneas que representa dicha relación.
A su vez usa un lenguaje que permite realizar la codificación de manera declarativa llamado Cypher, parecido al SQL.
En el siguiente enlace podrán ver su documentación que es bastante sencilla e intuitiva.
https://neo4j.com/developer/cypher/
Algunas de las funcionalidades y usos que nos aporta
Neo4j por ser una BD orientada a grafos nos permite hacer uso de una comunicación y obtención de datos con mayor velocidad indistintamente del volumen de nodos que existan, la posibilidad de predicción de información según el modelado que se haga de dicha BD potenciando lo que es IA (inteligencia artificial), un claro ejemplo es la plataforma Instagram o Facebook, que a más de uno de nosotros con tan solo hablar de un tema en específico con colegas o familiares estas plataformas a través de sus algoritmos dentro de la estructura de BD por grafos es capaz de mostrar información altamente relacionada.
Otro de los usos que nos permite es definir bien el ámbito en donde quisiéramos crear dicho BD, teniendo en cuenta las aplicaciones en donde es más usada como: redes sociales, clasificación en aplicaciones médicas, sistemas de recomendación, detección de patrones, sistemas aeroportuarios entre otros.
La seguridad es otra de las grandes funcionalidades que nos aporta debido al sistema de replicas que garantiza la persistencia de datos, el alto rendimiento, y la alta disponibilidad mediante clustering.
¿Por qué y para que Arquitecturas Neo4j?
Bueno como todos sabemos todo tiene una manera de hacer las cosas para conseguir que sean más eficaces a nivel de rendimiento, funcionalidad, portabilidad, escalabilidad, entre otros conceptos que hagan que nuestros desarrollos sean óptimos.
Una de ellas y no menos importante es la/s arquitecturas que se pueden implementar con Neo4j.
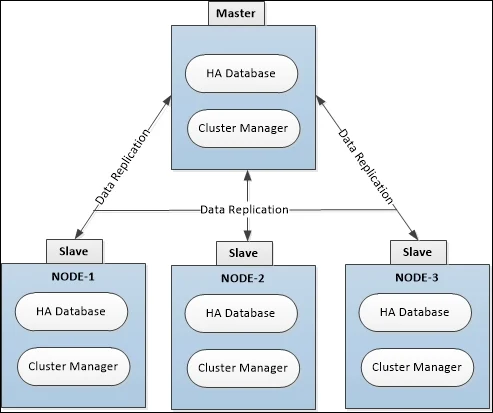
Arquitectura High Available Clúster
Esta arquitectura se compone por una instancia principal llamada Master y cero o más instancias llamadas Slaves(secundarias), tanto la Master como la Slave tiene replica y copia de toda la Base de datos, mantienen una comunicación bidireccional, teniendo en cuenta que las Slave(secundarias) se comunican con la Master para obtener las actualizaciones necesarias. En el caso que las escrituras se realicen sobre la Master al finalizar automáticamente se propagan a las Slave, y en el caso que se realicen en la secundaria esta se propaga a la principal, tomando en cuenta que no se considera exitosa hasta que no se escriba en la principal (master).
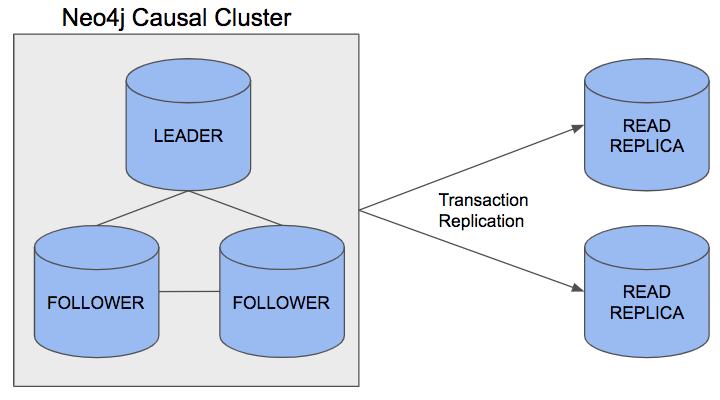
Arquitectura Casual Clúster
Esta arquitectura la constituyen dos componentes: Core Server, Read replicas.
Core Server: Su principal objetivo es guardar los datos siguiendo el protocolo Raft( podrán encontrar la documentación en el siguiente enlace: https://raft.github.io/ , de esta manera se determinará exitosa la escritura si al menos a la mitad de los Core Server se le ha propagada la información dada por un cliente.
Read replicas: Su principal objetivo es escalar el trabajo de las operaciones de lectura entre sí, y cada determinado tiempo envían una petición asíncrona a cualquiera de los Core Server para recibir una copia actual de los datos.
Esta arquitectura la constituyen dos componentes: Core Server, Read replicas.
Core Server: Su principal objetivo es guardar los datos siguiendo el protocolo Raft( podrán encontrar la documentación en el siguiente enlace: https://raft.github.io/ , de esta manera se determinará exitosa la escritura si al menos a la mitad de los Core Server se le ha propagada la información dada por un cliente.
Read replicas: Su principal objetivo es escalar el trabajo de las operaciones de lectura entre sí, y cada determinado tiempo envían una petición asíncrona a cualquiera de los Core Server para recibir una copia actual de los datos.
En resumen, Neo4j es una BD orientada a grafos que nos permite un alto rendimiento, escalabilidad, persistencia de datos, seguridad, entre muchas más ventajas para el desarrollo de aplicaciones con alta densidad de datos y con un alto acoplamiento en cuanto a la relación de los mismos.
Este artículo está dividido en 5 partes:
- 1. Introducción
- 2. Stack tecnológico
- 3. Ejemplo de uso
- 4. Ventajas y desventajas
- 5. Conclusiones
1. Introducción
En este apartado se tratará el uso de Neo4j y que nos aporta para el desarrollo de software.
2. Stack tecnológico
Sistema operativo: Windows 10
Aplicación de escritorio: Neo4j descarga en https://neo4j.com/download-neo4j-now/?gclid=CjwKCAjwp7eUBhBeEiwAZbHwkcghZGrGsqDCbV6HPQonP6hi7SeAgY3pp5m18ofrWEV17bMmwRSBRoCINoQAvDBwE
3. Ejemplo de uso
Es importante destacar que todo nace de la escritura de manera declarativa a través del lenguaje Cypher como anteriormente en este artículo se menciona, tomando en cuenta que es un lenguaje similar al SQL, por lo que mostrare varios de sus implementaciones.
Cypher está compuesto por nodos, etiquetas, propiedades y relaciones. Los nodos están constituidos por etiquetas o labels que a su vez pueden o no contener propiedades, de igual manera que las relaciones.
Una vez descargada a la aplicación de escritorio debemos tener en cuenta que ya contiene un ejemplo (Demo) del cual podremos ver varias de las definiciones y usos del lenguaje Cypher.
Nota: las comillas dobles (“”) tendrán que ser reescritas en la aplicación ya que la sintaxis cambia, aunque sean el mismo símbolo.
¿Cómo crear un nodo?
Pensemos en un nodo como un objeto atómico que contiene toda la información necesaria basada en un concepto único por ejemplo futbol.
CREATE (): Nodo anónimo
CREATE(Valencia): Nodo denominado Valencia
CREATE (Valencia: equipo) Nodo Valencia del tipo equipo
CREATE (Valencia: equipo {nombre: “Valencia FC”, descripción: “equipo de primera división”, integrantes: 22}): Nodo denominado Valencia del tipo equipo con dos propiedades en formato JSON.
¿Cómo crear relaciones entre nodos?
Una vez que hemos creado un nodo o varios nos interesaría comenzar a relacionarlos.
CREATE (Valencia: equipo {nombre: “Valencia FC”, descripción: “equipo de primera división”, integrantes: 22})- [: futbol]-> (Getafe: equipo {nombre: “GETAFE”, descripción: “equipo de primera división”})
En este caso se relacionan dos equipos de futbol de primera división.
¿Cómo borrar un nodo en particular?
Una de las maneras de eliminar un nodo es:
MATCH(n:Etiqueta) DELETE n
MATCH (Valencia: equipo) DELETE Valencia o MATCH (valencia) DELETE Valencia
¿Qué hacemos si el nodo tiene relaciones para eliminarlo?
Si el nodo tiene relaciones, habría que eliminar primero las relaciones antes que el nodo, ya que, si no nos daría un problema la ejecución del comando por dicha casuística, la sentencia para realizarlo sería:
MATCH (Valencia: equipo) DETACH DELETE Valencia
Existe un problema y es que este borrado no es recomendable para grandes volúmenes de datos, por lo que se recomienda eliminar por lotes cuando es el caso.
MATCH (Valencia:equipo) WHERE valencia.rivales>18
WITH Valencia LIMIT 1000
DETACH DELETE Valencia
RETURN count(*);
¿Cómo actualizar o añadir propiedades un nodo?
Actualizar o añadir propiedades a un nodo es con la sentencia SET al igual que en el lenguaje SQL.
MATCH (Valencia:equipo) WHERE Valencia.nombre =”Valencia FC”
SET Valencia.plantilla = 30
RETURN Valencia;
En el caso que la propiedad plantilla no exista la añade y sino la actualiza.
¿Cómo eliminar propiedades?
Al igual que para actualizar o añadir propiedades se utiliza el comando REMOVE
MATCH(Valencia:equipo) WHERE Valencia.nombre=”Valencia FC”
REMOVE Valencia.descripcion
RETURN Valencia
¿Cómo realizar consultas?
Las consultas se realizan con el comando MATCH similar al comando SELECT en el lenguaje SQL.
Tenemos que tener en cuenta los operadores para realizar diferentes tipos de consulta
Listado de Operadores:
Operadores de Matematicas: ,+,-,*,/,%,^
Operadores de Comparación: +, <>, <, >, <=, >=
Operadores Boleanos : AND, OR, XOR, NOT
Operadores String: +
Operadores de lista: IN (X..Y)
Operadores de relación de String: STARTS WITH, ENDS WITH , CONSTRAINSTS
Ejemplos:
MATCH(Valencia) RETURN Valencia : Consulta todos los nodos Valencia
MATCH (Valencia:equipo) RETURN Valencia: Consulta todos los nodos Valencia del tipo equipo
MATCH rivales= (Valencia:equipo)-[:futbol]->(Villareal:equipo) RETURN rivales: Consulta todos los rivales entre el valencia y villareal como equipos de futbol.
MATCH rivales= (Valencia:equipo)-[:futbol]->(Villareal:equipo) WHERE Valencia.nombre=”Valencia FC” RETURN rivales: Consulta todos los rivales entre los equipos Valencia y Villareal que esten asociados al club de Valencia FC.
MATCH (n)
RETURN count(n) : Devuelve la cantidad de nodos
MATCH()->() RETURN count (*) : Devuelve la cantidad de relaciones que existen
Uso de la cláusula ORDER BY
Al igual que en SQL se utiliza la cláusula ORDER BY para determinar el orden en los resultados de una consulta.
MATCH (Valencia:equipo)
WHERE 20< Valencia.edadJugadores< 30
RETURN Valencia
ORDER BY Valencia.nombreJugadores DESC: Consulta y ordena de manera descendiente por el nombre de los jugadores la cantidad de jugadores que tengan entre 20 y 30 años en la plantilla del equipo Valencia.
Uso de la cláusula DISTINCT
Se utiliza de igual manera que en el lenguaje SQL para devolver valores no repetidos.
MATCH (Valencia:equipo{ nombre:”Valencia FC”})-[:rivales]->(Getafe:equipo{nombre:”Getafe FC”})
RETURN DISTINCT Valencia.nombre, “rivales”,getafe.nombre: Devuelve todos los rivales entre valencia y getafe.
Uso de comparación de cadenas de caracteres:
MATCH (n)
WHERE n.nombre STARTS WITH ‘Ar’
RETURN n
MATCH (n)
WHERE n.nombre ENDS WITH ‘Ar’
RETURN n
MATCH (n)
WHERE n.nombre CONTAINS ‘Ar’
RETURN n
Tengamos el primer contacto con la aplicación de Neo4j de escritorio una vez descargada
Al abrir la aplicación, se puede observar que en el menú de la izquierda en la parte superior muestra la opción de “New” para crear proyectos, que serán mostrados en el panel tal y como se encuentra por defecto el “Example Project”
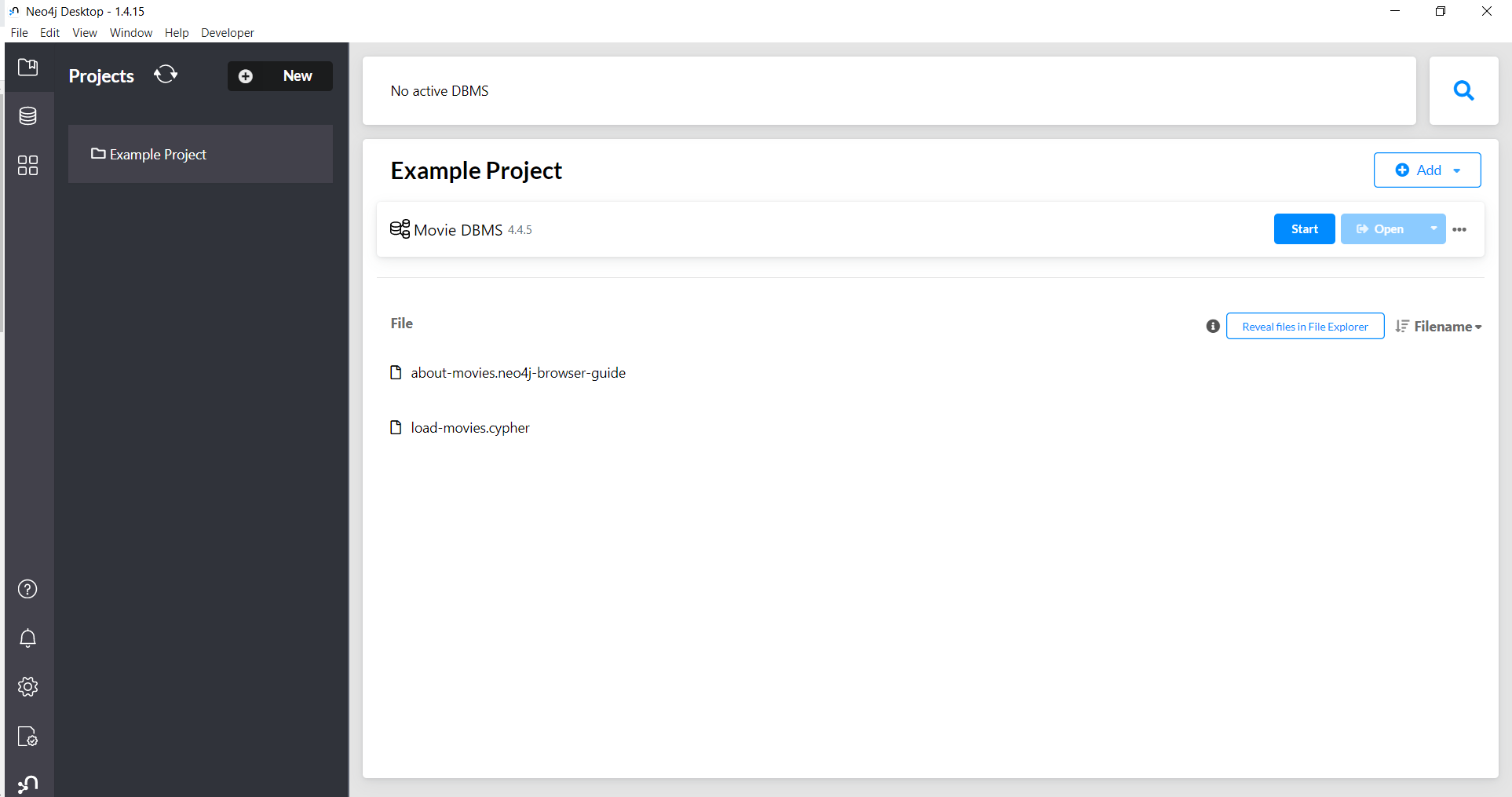
Iniciar la BD presionando el botón de start mostrado en la imagen anterior
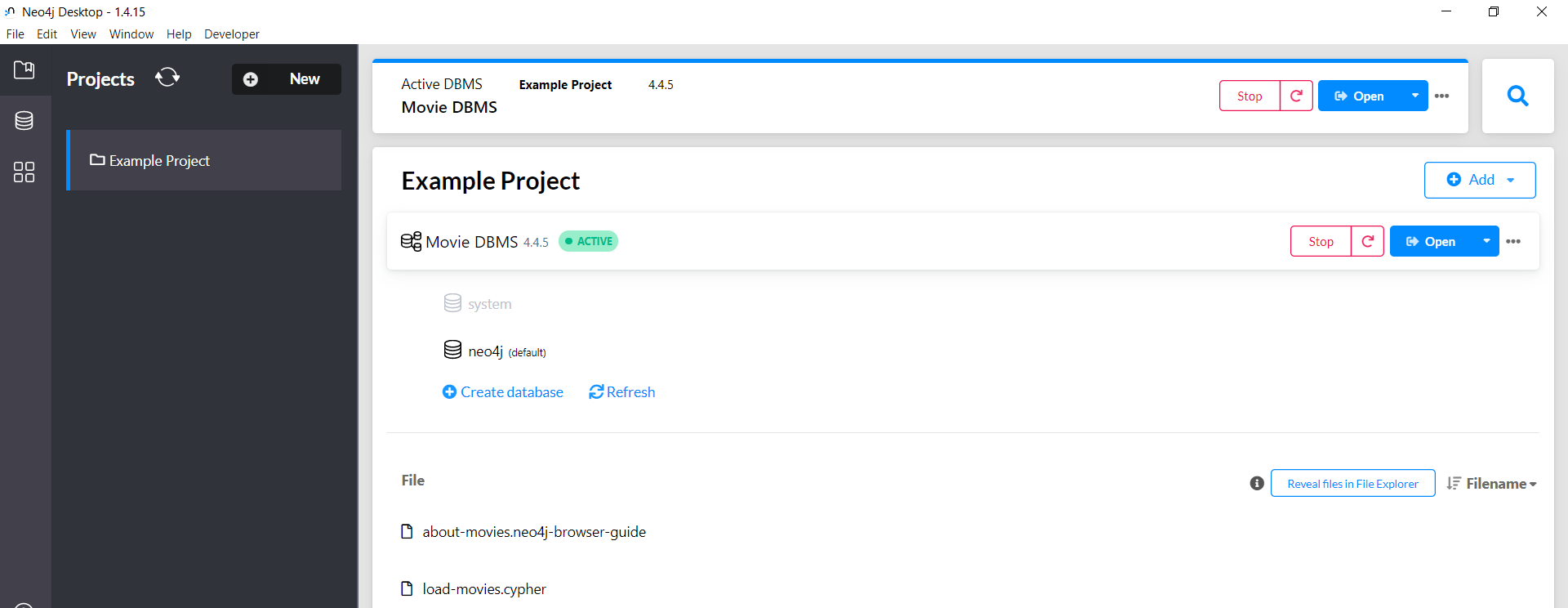
Abrir la BD una vez iniciada y en estado active, hacemos click en el botón de open
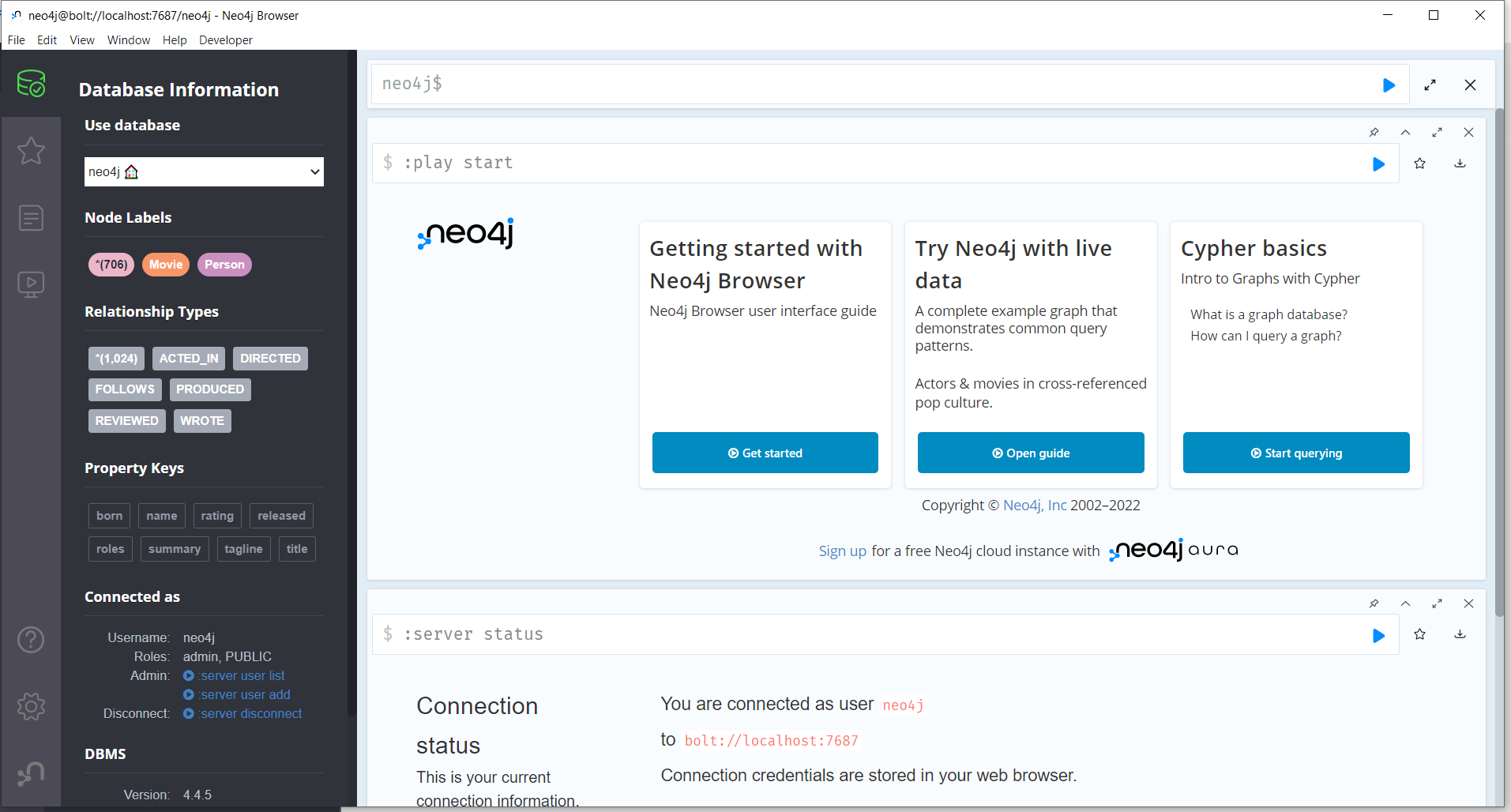
En el panel o menú del lateral izquierdo conseguiremos todas las herramientas y funciones para el modelado, incluye las relaciones y nodos existentes. Mientras que en la parte superior encontraremos una caja de texto libre para poder codificar con Cypher.
4. Ventajas Neo4j:
- Modelo de datos fácil de representar directamente conectados.
- Implementa consultas referidas a la estructura de grafos, gracias al uso de algoritmos como Dijsktra.
- Mapeo simple del grafo utilizando lenguajes como: Java, Ruby, C#, phyton.
- Altamente disponible y tolerante a la partición.
4.1 Desventajas Neo4j:
- Modelo de datos no estandarizado.
- Cypher no es un lenguaje estandarizado.
- Replicación de grafos no de subgrafos.
5. Conclusiones
Una de las grandes dudas que me surgió con esta tecnología era el alcance, utilidad y valor agregado que me ofrecería de cara al uso y no optar por otras BD NoSQL como MongoDb, MariaDb entre otras. Finalmente me he dado cuenta la facilidad de implementarlo, el UI de escritorio que proporciona y la cantidad de ventajas como: alto rendimiento, escalabilidad, replicas que hacen que me decante claramente para utilizarla en sistemas con alto volumen de datos y con la necesidad de conseguir un bajo tiempo de respuesta entre consultas de datos relacionados.
Con la explicación de este articulo espero podáis realizar proyectos, POCS (Pruebas de concepto) o ejemplos con la plataforma de Neo4j y ver su utilidad, sacándole todo el provecho y potenciando más aun vuestras aplicaciones.
Ahora solo queda que pongáis en marcha y espero tengáis el mínimo de dificultades para hacer uso de ella.
Espero os haya sido muy interesante y mucha suerte.