
Dominando las expresiones regulares: El arte de buscar y validar patrones (II)
Publicado por Cristóbal Martínez el
En el primer artículo de la serie (leelo aquí) nos iniciamos en las expresiones regulares y vimos las características más básicas.Por ejemplo, el uso de los literales, el (.), los rangos ([]), las clases de caracteres (\s \S \w \w \d \D), los saltos de línea (\n), (\r\n), (\r), el uso de grupos (()) incluyendo los grupos de captura con las backreferences y los grupos sin nombre, anclas y cuantificadores.
Con esas herramientas pudimos empezar a construir nuestras expresiones regulares. Si todavía no lo has leído te recomiendo que le eches un vistazo, además de aspectos básicos, se cuenta como leer los gráficos de los ejemplos que seguiré usando en esta entrada, y hay una chuleta muy interesante sobre las expresiones regulares que puede servir de referencia para consultas futuras.
Si todavía estás ahí, en esta entrada seguimos avanzando con en el uso y conocimiento de las expresiones regulares, con lo que en el post anterior denominamos conceptos menos básicos.

De la misma manera que en la entrada anterior, dejo un índice de los contenidos que vamos a ver. La entrada está estructurada en tres secciones, en la primera veremos todo lo que nos queda sobre las expresiones regulares, como grupos de captura, condicionales o aserciones. A continuación, hay una sección de bonus con un par de comandos para terminal Linux muy útiles y relacionados con lo que estamos viendo, seguida de la sección final con un resumen de lo visto en las dos entradas del blog, así como algunos ejemplos, consejos y la construcción de una expresión regular completa, los enlaces y referencias. Nos dejamos de rollos y vamos directamente al contenido.
Indice de contenidos
- Conceptos menos básicos
- Bonus track
- Para ir cerrando
Expresiones ávidas o perezosas (?)
He estado repitiendo que las expresiones regulares son ávidas y que buscan tantas coincidencias como sea posible. Quieren abarcar la mayor cantidad de caracteres que cumplan con el patrón. pero ¿eso es así siempre o podemos hacer algo para que se "conformen" con una coincidencia menor?
El meta-carácter (?) tiene otro uso, hacer las expresiones perezosas, de manera que los cuantificadores perezosos buscan la menor cantidad de coincidencias posible. Son más modestos y se detienen al encontrar la primera coincidencia.
Vamos a verlo con ejemplo y comparamos el resultado de la misma expresión ávida y perezosa. En este caso busco grupos de letras dentro de una frase, como mínimo deben ser dos y no hay un límite superior:
Expresión ávida:


Expresión perezosa:


Pongo las dos imágenes juntas para poder ver las diferencias, si miras con atención las dos imágenes podrás apreciar que en el caso de expresiones ávidas hacen match con la expresión de mayor tamaño posible. Mientras que en el caso de las expresiones perezosas la coincidencia se produce con la cadena de menor tamaño.
Vamos a sintetizar en un cuadro las diferencias entre expresiones y cuantificadores ávidos y perezosos. En todos los casos vamos a usar el mismo texto de prueba (abbb) de manera que al usar un cuantificador aplicado a la letra b podemos ver claramente las diferencias entre los cuantificadores ávidos y perezosos.
- Expresiones ávidas, comportamiento por defecto
| Texto | Expresión ávida | Resultado | Comentario |
|---|---|---|---|
| abbbb | ab* | abbbb | 0 o más, busca el mayor posible -> 4 |
| abbbb | ab+ | abbbb | 1 o más, busca el mayor posible -> 4 |
| abbbb | ab? | ab | 0 o 1, busca el mayor posible -> 1 |
| abbbb | ab{2,3} | abbb | 2 a 3, busca el mayor posible -> 3 |
- Expresiones perezosas
| Texto | Expresión perezosa | Resultado | Comentario |
|---|---|---|---|
| abbbb | ab*? | a | 0 o más, busca el menor posible -> 0 |
| abbbb | ab+? | ab | 1 o más, busca el menor posible -> 1 |
| abbbb | ab?? | a | 0 o 1, busca el menor posible -> 0 |
| abbbb | ab{2,3}? | abb | 2 o 3, busca el menor posible -> 2 |
Como vemos es las tablas de ejemplo las expresiones ávidas buscan siempre la mayor coincidencia posible, mientras que las perezosas buscan siempre la menor coincidencia posible, incluso si es 0.
Ávidos:
*: Coincide con el elemento anterior cero o más veces. a* encuentra “a”, “aa”, “aaa”, etc.+: Coincide con el elemento anterior una o más veces. b+ encuentra “b”, “bb”, “bbb”, etc.?: Coincide con el elemento anterior cero o una vez. b? encuentra “b”.{n}: Coincide con el elemento anterior exactamente n veces. c{3} encuentra “ccc”.{n,}: Coincide con el elemento anterior al menos n veces. d{2,} encuentra “dd”, “ddd”, “dddd”, etc.Perezosos:
*?: Coincide con el elemento anterior cero o más veces de manera perezosa.+?: Coincide con el elemento anterior una o más veces de manera perezosa.??: Coincide con el elemento anterior cero o una vez de manera perezosa.{n}?: Coincide exactamente n veces de manera perezosa.{n,}?: Coincide de n a m veces de manera perezosa.Grupos ()
Un grupo de captura no es más que una forma de indicarle a la expresión regular que trate todo lo que hay dentro de un paréntesis como un conjunto único, es un subpatrón dentro del patrón principal. Esto puede ser útil para aplicar cuantificadores a varias partes de la expresión, para aplicar operadores a subexpresiones completas o para capturar partes específicas de una cadena.
Vamos a buscar la cadena (tata) dentro del texto objetivo "tatarabuelo", con lo que hemos visto hasta ahora la expresión podría escribirse como (tata) , pero con los grupos podemos forzar a que la expresión busque la cadena (ta) dos veces consecutivas:
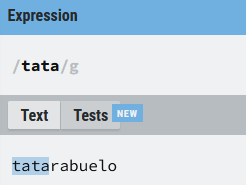
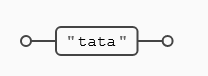
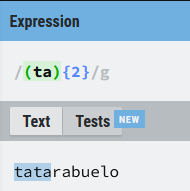
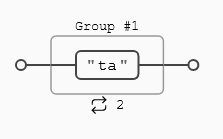
Podemos apreciar que el cuantificador {2} se aplica a todo lo que hay dentro del paréntesis y no sólo a la vocal a (la expresión ta{2} busca una (t) seguida de dos vocales (a) consecutivas).
Hemos utilizado una expresión simple para ejemplificar el uso de grupos, pero evidentemente se pueden usar todo tipo de expresiones complejas y anidaciones así como todo tipo de modificadores sobre el grupo, (?), (+), (*)...
Por ejemplo:
\b((file_)?\w+).pdf$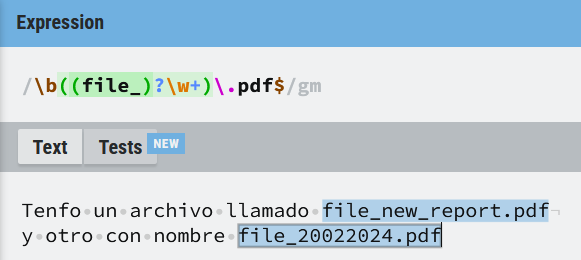
Esta expresión tiene dos grupos de captura anidados, el primero coincidirá con grupos de caracteres (1 o más), separados de un espacio y un grupo de números (uno o más), mientras que el segundo grupo de captura coincidirá sólo con los números.
Solamente con esto los grupos ya son de gran utilidad en la confección de nuestras expresiones regulares, pero todavía podemos darle una vuelta de tuerca más para hacerlos más poderosos a la hora de emplearlos.
Grupos de captura y backreferences
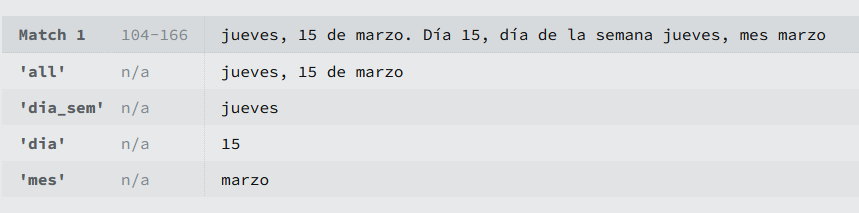
Volvamos al ejemplo que veíamos al principio del post, en que buscábamos una fecha, y el separador entre días y meses era libremente elegido por el usuario entre (/) o (-), pero queríamos que usara siempre el mismo y no los mezclara.
En ese momento proponíamos una expresión regular del tipo (\d\d[-/]\d\d[-/]\d\d\d\d), hemos ido avanzando y ahora creo que estamos de acuerdo en que podemos simplificar a algo similar a esto(\d{2}[-/]\d{2}[-/]\d{4}):
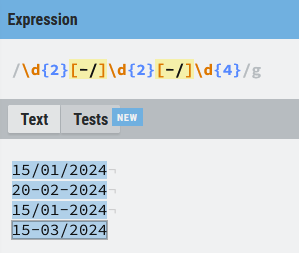
La expresión ha mejorado, pero sigue sin resolver el problema planteado, queremos que el separador sea siempre el mismo y como vemos en la ilustración superior no pasa, aquí es donde entran en juego los grupos de captura y las backrefereces. Podemos traducir backreference como retro referencia, o referencia a algo anterior, concretamente un grupo de captura.
Cada vez que pongo algo entre paréntesis, la expresión regular lo captura y es capaz de recordarlo para su uso posterior. Dependiendo del motor de expresiones regulares que estemos usando, esta referencia tiene un formato u otro, en este caso usaremos (\num), donde (num) representa el número de paréntesis que ha aparecido en la expresión regular empezando a contar por la izquierda.
¿Cómo...? Es más sencillo de lo que parece, lo vamos a ver sobre el ejemplo de las fechas, evolucionamos la primera expresión a la segunda:


Vamos a empezar a leer la expresión de izquierda a derecha para ver los cambios:
- dos dígitos (
\d{2}) para el día - introducimos un grupo de captura, el primero, por tanto, su backreference será (
\1). Que debe contener un (-) o un (/) - dos dígitos más (
\d{2}) para el mes - (
\1) que significa que debe coincidir con lo recogido por el primer grupo de captura - cuatro dígitos (
\d{4}) para el año.
Por consiguiente, lo que le estamos indicando, es que el símbolo capturado entre los días y los meses debe ser lo mismo que lo capturado entre los meses y el año, y como vemos en la ilustración funciona:
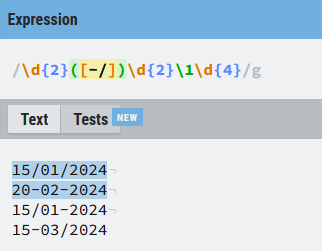
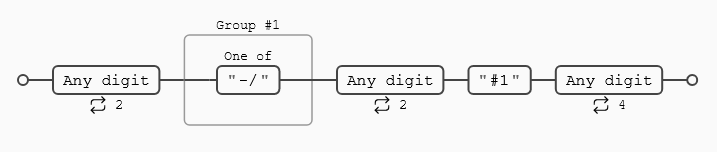
La expresión regular sigue sin ser perfecta, porque haría coincidencia con una fecha del tipo 50/13/2024, pero la afinaremos más según avancemos.
Vamos a ver otro ejemplo que incluye grupos, anidaciones y backreferences:
((\w+), (\d{1,2}) de (\w+))\. Día \3, día de la semana \2, mes \4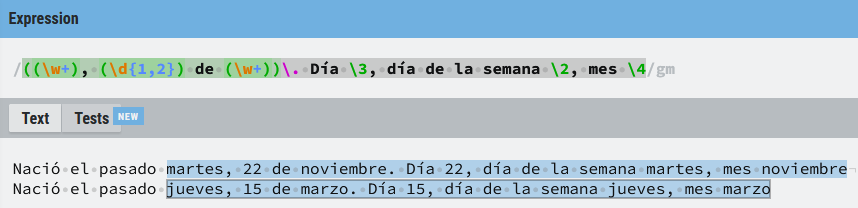

Donde, si contamos de izquierda a derecha:
- El primer grupo de captura se corresponde con (
((\w+), (\d{1,2}) de (\w+))). - El segundo grupo de captura (
\2) es la primera ocurrencia de (\w+). - El tercer grupo de captura (
\3) es (\d{1,2}). - El cuarto grupo de captura (
\4) es la segunda ocurrencia de (\w+).
En la página de https://regexr.com/ que estamos usando hay una parte de herramientas en las que se pueden ver los grupos de la expresión regular:
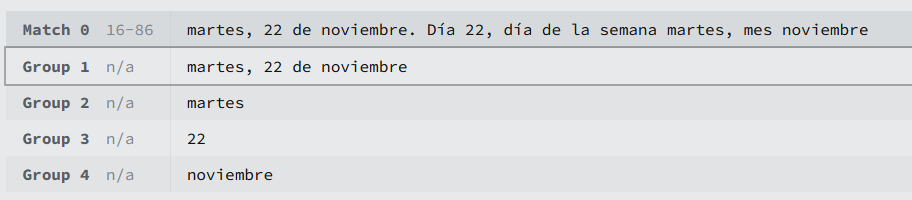
En resumen, los grupos en expresiones regulares permiten agrupar y organizar partes del patrón. Los grupos de captura, además, almacenan la parte coincidente para su posterior referencia. Esto es útil para realizar búsquedas más complejas y extraer información específica de las cadenas de texto.
Grupos de captura con nombre
Como ves el uso de grupos de captura y backreferences puede llegar a ser muy potente, pero también dificulta un poco la lectura de la expresión regular. En algunos lenguajes de programación que implementan las expresiones regulares será posible acceder al contenido del grupo de captura a través de un nombre arbitrario que introducimos en la expresión regular, pero usualmente el acceso es a través de la posición que ocupa.
De cualquier manera vamos a ver como se introduce un nombre en un grupo de captura, mediante la expresión:

Lo vemos con un ejemplo:
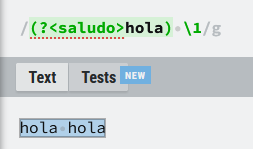
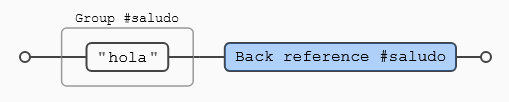
Expresiones utilizadas:
- Para dar nombre a un grupo de captura (
(?<nombre> expresión)) - Para usar un grupo de captura con nombre (
\k<nombre>)
Es cierto que la nomenclatura usada en el ejemplo es específica de javaScript y que puede variar en los diferentes lenguajes de programación o motores de búsqueda, pero en algún lenguaje había que hacer el ejemplo.
Vamos a ver el mismo ejemplo que vimos en los grupos de captura con nombre y así podemos comparar ambas opciones, y veremos de qué forma es más sencillo identificar y referirse a un grupo de captura cuando hay varios y se encuentran anidados como es el caso.

Usando la herramienta que nos provee la página que estamos usando para probar las expresiones regulares podemos apreciar lo sencillo que es identificar cada uno de los grupos por su nombre:
Grupos que no capturan.
¿Es necesario que siempre que hacemos uso de los (()) el grupo resultante sea un grupo de captura? La respuesta es que no, hay una forma de indicarle al motor de expresiones regulares que los valores del paréntesis forman un grupo, pero que no queremos usarlo más tarde y que por tanto no es necesario que lo capture y, por ende, no podremos acceder con una backreference. Para ello basta con poner ((?:) al inicio del grupo. Vamos a verlo con una expresión que ya hemos usado antes:
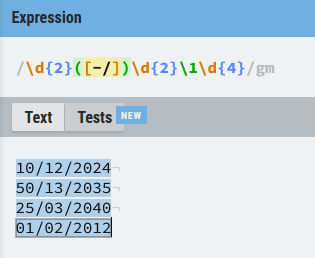

Si hacemos que el grupo no sea de captura con (?:) ocurren dos cosas:
- La backreference deja de funcionar (en la imagen se ve como tiene un color rojo en lugar del verde que veíamos antes)
- La expresión regular no funciona, por un error al no encontrar (
\1) que habría que sustituir, por ejemplo, por ([-/]) para que la expresión volviera a ser funcional.

Con estas herramientas ya se pueden hacer expresiones más que interesantes, pero aún no hemos visto todas sus capacidades. ¿Te quedas y seguimos?
Alternancia (|) Operador or
Se representa en las expresiones regulares con el meta-carácter (|), también llamado barra, pipe o tubería. Sirve para indicarle al motor de expresiones que tiene la posibilidad de elegir entre varias opciones separadas por el símbolo (|). Hemos visto algo parecido con los ([]), donde por ejemplo con ([ab]) un carácter podía ser o (a) o (b), pero la gran diferencia es que los corchetes funcionan a nivel de carácter, mientras que la alternancia funciona a nivel de expresión.
Supongamos que tengo una lista de nombres y quiero localizar a las personas que se apellidan Martínez, pero sólo a los que se llaman Juan o Marc:
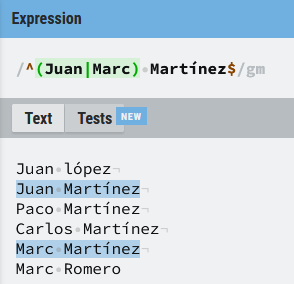
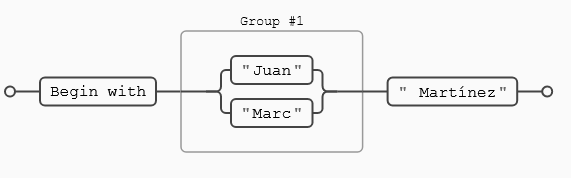
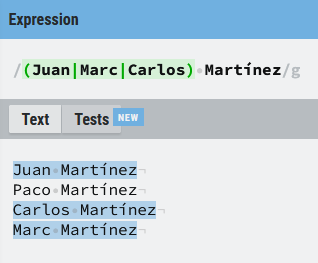
Como ves funciona a nivel de expresión, busca a los Juan o Marc que se apelliden Martínez. Si quiero añadir más nombres no tengo nada más que ir añadiendo elementos separados por (|).
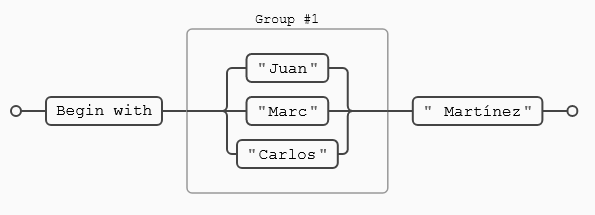
Este es un buen momento para recupera el problema que teníamos a medias con las fechas de tipo 50/13/2023, lo usaremos para ver las posibilidades de la alternancia. La expresión a utilizar será esta:
^(0[1-9]|[12][0-9]|3[01])([/-])(0[1-9]|1[0-2])\2\d{4}$
Es larga así que vamos a verla por partes, aunque ya tenemos conocimientos para entenderla.
- (
^): Inicio de la cadena. - (
(0[1-9]|[12][0-9]|3[01])): Grupo para el día. Puede ser un día del 01 al 31, vamos a verlo por partes:- (
0[1-9]) Son los días del 01 al 09 (formato de 2 dígitos) - (
[12][0-9]Son los días del 10 al 29. Un número es o 1 o 2 y el segundo es cualquier número del 0 al 9. 10,11,12.... 29. - (
3[01]) Son los días 30 o 31
- (
- (
[/-]): Separador de día y mes, una (/) o un (-). (0[1-9]|1[0-2]): Grupo para el mes. Puede ser un mes del 01 al 12. Es similar al formato para los días, Vamos a verlo por partes:- (
0[1-9]) Son los meses de 01 a 09 - (
1[0-2]) Son los meses 10, 11 y 12. Un 1 con un 0, un 1 o un 2
- (
- (
\2): Separador de mes y año, que debe ser igual que el separador día y mes. Es el segundo grupo de captura de la expresión, por tanto (\2) por su posición.- Si en la expresión hubiera puesto (
^(?:0[1-9]|[12][0-9]|3[01])) haciendo que el primer grupo no fuera de captura, la expresión correcta hubiera sido (b), al ser primer grupo de captura de la expresión.
- Si en la expresión hubiera puesto (
- (
\d{4}): Cuatro dígitos para el año. - (
$): Coincide con el final de la cadena.
Condicionales
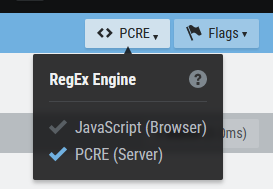
Lo primero a destacar, es que no todos los motores de búsqueda soportan este formato, para trabajar con ellos en la página en la que estamos haciendo las pruebas hay que cambiar el motor de JavaScript a PCRE, en un desplegable que hay en la parte superior derecha de la web
Este tipo de expresiones permiten especificar diferentes patrones, en función de si una determinada condición se cumple o no. Vamos a ver el formato en que se escriben:
(?(?=condición) Si verdadero | Si falso)Donde:
- Condición es la expresión a evaluar
- Si se cumple se aplica la expresión Si verdadero
- Si no se cumple se aplica la expresión Si falso
Lo vamos a ver más claro con un ejemplo, lo analizamos por partes:
^(?(?=^[1-9]\d*)\d+|0[1-9]\d*)$Tengo la estructura condicional donde:
- La condición es (
^[1-9]\d*) que la línea empiece por un número del 1 a 9, seguido de 0 o más números - Si se cumple: la expresión regular analiza si la línea está compuesta de números (
\d+). - Si no se cumple, es decir, que la línea empieza por un 0 o cualquier carácter o símbolo, la expresión a utilizar es esta: (
0[0-9]\d). Es decir será válida si empieza por 0 seguido de cualquier otro número de 1 a 9 ([1-9]) y un número indeterminado de dígitos (\d*).
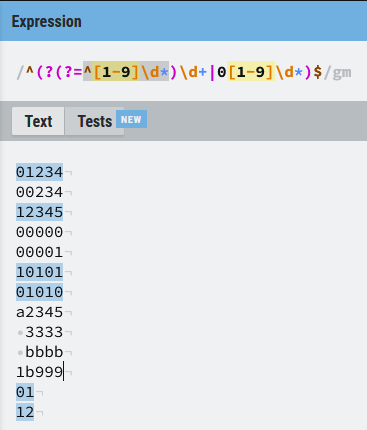
Comprobamos que los únicos resultados válidos son aquellas líneas que empiezan por un número que no sea 0 y todos los caracteres son numéricos, o aquellas líneas que empiezan por 0 y en la segunda posición no hay un cero y todos los caracteres son numéricos. Este tipo de expresiones son complicadas de ver, así que si es la primera tómalo con calma, te recomiendo que practiques hasta que cojas un poco de práctica con ellas.
Otro ejemplo combinando el condicional con un grupo de captura:
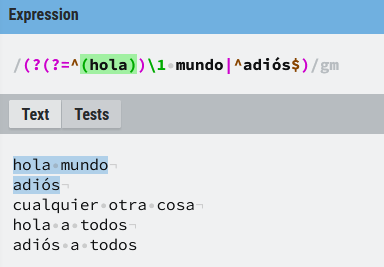
El objetivo es que si la frase empieza por hola coincida con el famoso "hola mundo", en caso de no empezar por hola habrá coincidencia si la frase es "adiós", en cualquier otro caso no hay coincidencia.
Este tipo de expresiones se pueden complicar mucho, puesto que tanto la condición como los casos de verdadero o falso permiten expresiones regulares complejas, anidación, alternancia...
LookAround (aserciones)
En ocasiones para que se cumpla una expresión regular se deben dar más condicionantes que la simple coincidencia del patrón con la cadena objetivo. Se emplea cuando tenemos la condición que un patrón es precedido o seguido por otro patrón que debe cumplirse o no para que se dé la coincidencia. Hay que mencionar que las aserciones no consumen caracteres al analizar la expresión. Por ejemplo, busco todas las palabras de un texto, siempre que no tengan a continuación un (;) o la siguiente palabra no empiece por a...
Para este tipo de casos usamos lookaround, algo así como mirar alrededor. Hay dos posibles opciones, que a su vez se subdividen en dos subcasos más:
- Lookahead (mirar hacia adelante)
- Positivo (?=)
- La expresión debe ser seguida un texto que satisfaga el lookahead positivo
- Negativo (?!)
- Vamos a tener coincidencia siempre que la coincidencia de la cadena objetivo no esté seguida de una cadena que satisfaga el lookahead negativo.
- Positivo (?=)
- Lookbehind (mirar hacia atrás)
- Positivo (?<=)
- La expresión debe ser precedida de un texto que satisfaga el lookbehind
- Negativo (?<!)
- La expresión debe ser precedida por un texto que no satisfaga el lookbehind
- Positivo (?<=)
Esto puede ser un poco confuso, quizá sea necesario un ejemplo para entender todo esto... Pues vamos a ello, que es más fácil de ver que de contar.
Lookahead positivo (?=)
casa (?=cama)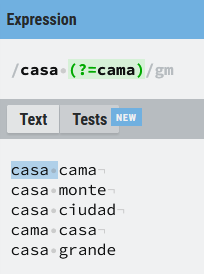
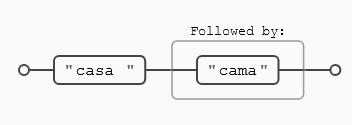
Busco todas aquellas ocurrencias de casa que estén seguidas de la palabra cama, en caso contrario no hay coincidencia.
Lookahead negativo (?!)
casa (?!cama)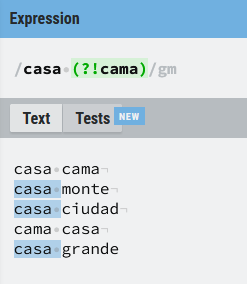
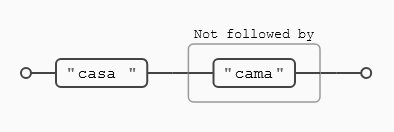
Aquí tenemos justo el caso contrario, busco todas aquellas ocurrencias de la palabra casa que no estén seguida de la palabra cama
Lookbehind positivo (?<=)
(?<=\.\s*)w+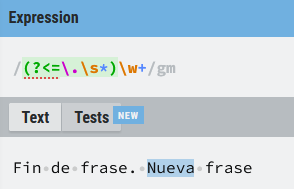
En este caso busco cualquier palabra que esté precedida de un . seguida de 0 o más espacios, en cualquier otro caso no hay coincidencia.
Lookbehind negativo (?<!)
(?<!\.\s*)\bw+\b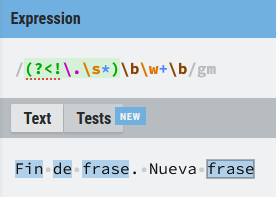

En este caso lo que busco son todas las palabras que no estén precedidas por un punto en el texto objetivo.
Algunos ejemplos más:
Podemos usar lookahead positivo, por ejemplo, para buscar palabras duplicadas consecutivas dentro de un texto:
(\b\w+\b)(?=.*\b\1\b)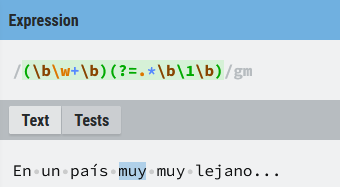

Ejemplo similar al de buscar palabras repetidas consecutivas pero usando lookbehind positivo:
(\b\w+\b)(?<=\b\1\b\s+\b\1\b)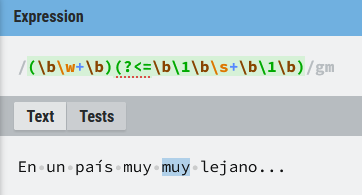

Vamos a ver un último ejemplo mezclando las funcionalidades de mirar hacia adelante y mirar hacia atrás. En este caso lo que busco es la palabra gato dentro de un texto, pero para que exista coincidencia se tienen que dar dos condiciones, si no se da alguna de ellas no hay coincidencia:
- Tiene que ir precedido de la palabra (
mi) y un espacio, observa que en la expresión he puesto un ancla. - Después de gato tiene que estar la palabra favorito, de nuevo hay un ancla por lo que por ejemplo favoritos no daría una coincidencia.
(?<=\bmi\s)gato(?=\sfavorito\b)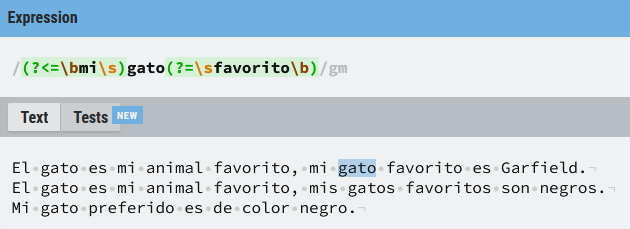

Para despejar las dudas que puedan surgir vamos a cambiar una de las condiciones para que no se tenga que dar, en lugar de que se tengan que dar ambas.
(?<=\b([Mm]i|[Ss]u)\s)(?<!\bpequeño\s)gato
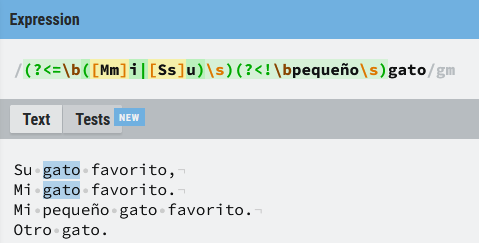
En este último ejemplo se da la coincidencia sólo la palabra (gato) va precedida por las palabras (mi) (Mi), o (su) (Su), pero no si va precedida de la palabra pequeño.
(?<=(\w+\s\w+\s))(?<!\bpequeño\s)gato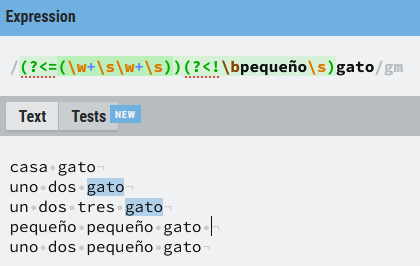
En esta variante de la expresión encuentra gato siempre que esté precedida de dos palabras y la anterior no sea pequeño.
Creo que ahora si ha quedado mucho más claro el uso de las aserciones.
Tenemos estas posibilidades:
- Lookahead positivo (?=)
- Lookahead negativo (?!)
- Lookbehind positivo (?<=)
- Lookbehind negativo (?<!)
Anidamiento
Hasta ahora hemos visto expresiones regulares sencillas y alguna un poco más compleja, por lo visto hasta ahora se sobreentiende que todas las características de la expresiones regulares se pueden anidar creando expresiones más complejas, aunque habíamos hecho mención explícita de esta característica, no está de más recordarlo. Una expresión regular puede albergar una cantidad indeterminada de grupos, además permite anidar tantos grupos como se desee para conseguir expresiones complejas.
Modificadores
En algunas ocasiones nos puede interesar modificar el comportamiento del motor de expresiones regulares, para ello tenemos la opción de pasar unos parámetros llamados modificadores, se suelen usar en los lenguajes de programación. Los más interesantes son estos:
- (?i) Insensitive. Hace la expresión regular insensible a mayúsculas / minúsculas.
- (?g) Global. Hace que el motor busque todas las ocurrencias.
- (?s) Modo de línea única. Hace que el (
.) haga match con todos los caracteres, incluido el salto de línea. - (?m) Modo de multilínea. Hace que los meta-caracteres (
^) y ($) hagan match al principio y final de cada línea y no sólo al principio y final del texto.
- i (insensitive),
- g (global),
- m (multilínea) o
- s (línea única).
Aquí termina la parte de conceptos más avanzados, con lo visto hasta el momento podremos construir un gran abanico de expresiones regulares aunque todavía quedan algunas cosas interesantes por ver.
Comandos de terminal Linux útiles greep y awk
Sólo como referencia vamos a introducir un par de comandos de terminal (Linux), a nivel muy básico, pero que son tremendamente potentes y a los que te recomiendo echar un vistazo.
Vamos a suponer que tenemos un fichero, por ejemplo agenda.csv, en el que tenemos un conjunto de nombres y teléfonos, vamos a suponer este contenido:
Nombre,Apellido,Dirección,Teléfono
Juan,García,Las Flores 123,555-1234
María,López,Calle Mayor 456,555-5678
Pedro,Martínez,Avenida Libertad 789,555-9012
Ana,Rodríguez,Plaza España 321,555-3456
Carlos,López,Calle Estrella 789,555-7890Haremos el ejercicio de buscar la línea donde aparece el numero de María usando los dos comandos
greep
El comando grep podría ser algo como esto:
grep "María" agenda.csvEste comando buscará todas las líneas que contienen el literal "María".

Si sólo quieres contar las entradas puedes usar la opción -c:
grep -c "María" agenda.csvawk
El comando awk es más potente, podríamos obtener sólo el campo de teléfono, en lugar de toda la línea de la siguiente manera:
awk -F ',' '$1 == "María" {print $4}' agenda.csv-F ','especifica que el delimitador de campos en el fichero es una coma.$1 == "María"es nuestra expresión regular, en este caso el literal "María".{print $4}imprime el cuarto campo, que es el teléfono, si se cumple la condición de búsqueda.

La gracia de ambos comandos es que permiten el uso de expresiones regulares por ejemplo, si buscas nombres que empiecen por P, o cualquier cosa que se te ocurra.
grep "^P" agenda.csvawk -F ',' '/^P/' agenda.csvSi sabes que la comparación la debe hacer en el primer campo podrías usar algo como esto:
awk -F ',' '$1 ~ /^P/' agenda.csvMis recomendaciones para construir una expresión regular 💡
Desde mi experiencia, estas son algunas recomendaciones que pueden ser útiles a la hora de escribir expresiones regulares.
Utiliza los cuantificadores más precisos posibles. Si conoces el número de repeticiones de un patrón es mejor usar ({n}) que (+) o (*).
Es mejor evitar en la medida de lo posible el uso del (.) ya que puede coincidir con cualquier cosa, siempre que sea posible es mejor usar caracteres concretos.
Si la lógica de la expresión lo permite es mejor usar clases de caracteres que alternancia, por ejemplo es mejor ([aeiou]) que ((a|e|i|o|u)). Siempre existen varias alternativas a la hora de construir una expresión regular, por ejemplo estas expresiones tienen el mismo resultado:
gray|greygr(a|e)ygr[ae]y
A la hora de escribir expresiones es mejor evitar todos los grupos de captura (()) que no sean necesarios para mejorar la lectura y el rendimiento. Úsalos cuando necesites usar cuantificadores o hacer alguna captura.
Intenta hacer trabajar lo menos posible al motor de expresiones, (Buenas tardes | Buenas noches) puede escribir como (Buenas (?:tardes|noches)).
Las aserciones son herramientas muy potentes, que además no consumen caracteres de la cadena cuando se aplican.
Las anclas pueden ser muy útiles si estás trabajando con palabras, a veces es mejor usar un anclar que partes de la palabra en el patrón.
Lo mejor es probar lo más posible una expresión regular para evitar sorpresas.
Consulta la documentación del motor de expresiones que vas a utilizar, algunos tienen capacidades adicionales o pequeñas variaciones.
Documenta tus expresiones, pasado un tiempo te ayudará a entender que querías, son complejas y no siempre sencillas de entender.
Ya tenemos todas las herramientas necesarias para construir nuestras expresiones regulares, las más sencillas se puede escribir directamente, pero las más complejas suelen requerir un pequeño proceso iterativo hasta que se consigue el resultado deseado. Un buen acercamiento consiste en descomponer el problema en partes más pequeñas y tratarlas por separado. Para cada una de esas partes es recomendable construir las expresiones regulares pasos a paso, probando y ajustando la expresión antes de avanzar.
Ejemplo práctico
Vamos a suponer que queremos validar una fecha con este formato dd/mm/yyyy y queremos construir una expresión regular, quizá un posible acercamiento sería el siguiente, dónde la idea es obtener una expresión que satisfaga nuestras necesidades, a partir de una expresión menos precisa que tomamos como aproximación inicial.
En una primera tentativa tendríamos una expresión como esta:
[0-9]{2}/[0-9]{2}/[0-9]{4}Como vemos no es demasiado precisa, porque da coincidencias con: dos dígitos cualesquiera / dos dígitos cualquiera/ cuatro dígitos cualesquiera. Con lo que 50/25/9999 sería una fecha válida.
Vamos a ir afinando cada una de las partes de la expresión por separado.(Divide y vencerás)
Empezamos afinando los días.
Introducimos el siguiente cambio [0123][0-9]. De esta manera, hemos mejorado un poco la expresión, ya sólo son válidos los días del 00 al 39 pero necesitamos más precisión.
El siguiente cambio lógico sería una expresión similar a esta ([012][0-9]|3[01]). Introducimos una alternancia de forma que ahora son válidos los días del 00 al 29 o el 30 o 31. Pero aún se puede mejorar un poco.
Ya casi lo tenemos, un último cambio de manera que la expresión queda así : (0[1-9]|[12][0-9]|3[01]). Introducimos una alternancia más de manera que ahora son válidos los días del 01 al 09 o los días del 10 al 29 o los días 30 y 31. Ya hemos resuelto de manera satisfactoria la parte de los días. Sería posible añadir un (?) detrás del primer cero de manera que fueran válidos tanto los días con formato 01, 02, 03... como los días con formato 1,2,3... (0?[1-9]|[12][0-9]|3[01])
Seguimos con los meses.
Hemos empezado con una expresión del tipo [0-9]{2} lo que implica dos dígitos cualesquiera del 00 al 99, de nuevo tenemos el formato, pero necesitamos más precisión.
En la siguiente iteración consideramos la expresión [01][0-9]. De esta manera reducimos el abanico de opciones de 00 a 19, pero sigue siendo insuficiente.
La expresión final queda (0[1-9]|1[012]). Introducimos una alternancia de manera que ahora son válidos los meses de 01 a 09 o los meses 10,11 o 12. Ya tenemos lo que necesitamos. De nuevo sería posible añadir un (?) detrás del primer cero de manera que fueran válidos tanto los meses en formato 01, 02, 03... como en formato 1,2,3... (0?[1-9]|1[012])
Por último, queda darles forma a los años.
Hemos empezado con una expresión del tipo [0-9]{4}, lo que podría ser suficiente para representar los años del 0000 al 9999, pero puede no ser una cifra realista en un formulario, vamos a intentar reducirlo.
En primera instancia introducimos un cambio para reducir el abanico posible de años válidos [12][0-9]{3}. Hemos conseguido reducir las posibilidades de 1000 a 2999, sigue siendo un poco ambiguo.
Vamos a intentar reducirlo un poco más (19[0-9]{2}|20[0-9]{2}). Tenemos una expresión válida de 1900 a 2099 que podría ser aceptable. Si quisiéramos afinar un poco más podríamos hacer algo como esto (19[5-9][0-9]|20[0-2][0-9]) que es válido de 1950 a 2029, o simplificando un poco (19[5-9]\d|20[0-2]\d).
Con lo que nuestra expresión uniendo las diferentes partes que hemos desarrollado por separado y simplificando [0-9] por \d quedaría:
(0[1-9]|[12][0-9]|3[01])/(0[1-9]|1[012])/(19[5-9][0-9]|20[0-2][0-9]) (0\d|[12]\d|3[01])/(0\d|1[012])/(19[5-9]\d|20[0-2]\d) Ya sólo queda probarla:
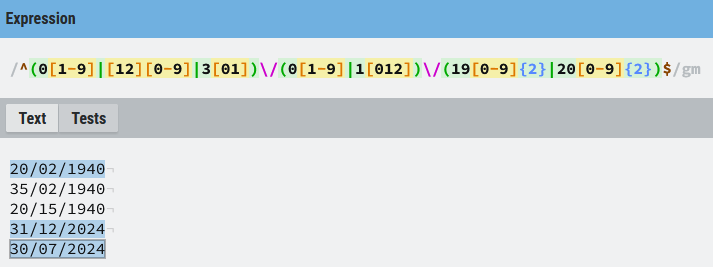
La expresión anterior tiene una funcionalidad básica, suficiente para la mayoría de las situaciones, si bien todavía no es capaz de diferenciar los meses de 30 o 31 días, ni valida correctamente si febrero tiene 29 o más días, nos ofrece una validación básica de una fecha. Si se necesita más precisión se puede recurrir a lenguajes de programación o librerías de terceros para las validaciones, lo que no quiere decir que no se puedan construir expresiones regulares para este tipo de validaciones, pero requiere de un esfuerzo considerable y no son nada mantenibles, hay que evaluar cada caso para tomar la decisión. De cualquier modo, vamos a ver una expresión más completa de ejemplo que valida de forma completa las fechas y te animo a que la pruebes:
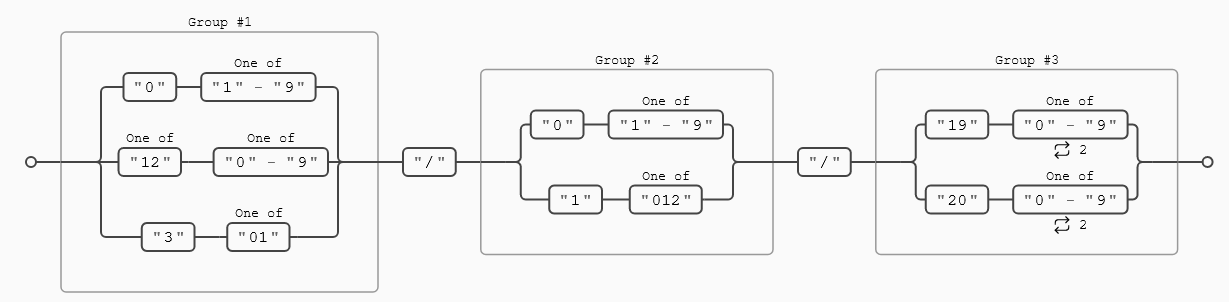
^(?:(?:31(\/|-|\.)(?:0?[13578]|1[02]))\1|(?:(?:29|30)(\/|-|\.)(?:0?[13-9]|1[0-2])\2))(?:(?:1[6-9]|[2-9]\d)?\d{2})$|^(?:29(\/|-|\.)0?2\3(?:(?:(?:1[6-9]|[2-9]\d)?(?:0[48]|[2468][048]|[13579][26])|(?:(?:16|[2468][048]|[3579][26])00))))$|^(?:0?[1-9]|1\d|2[0-8])(\/|-|\.)(?:(?:0?[1-9])|(?:1[0-2]))(\4(?:(?:1[6-9]|[2-9]\d)?\d{2}))$
Además, en la siguiente una imagen se puede apreciar la complejidad de la expresión anterior, la puedes usar guía para seguirla, con lo que hemos visto hasta ahora tenemos conocimientos más que suficientes para hacerlo, a pesar de lo aparatoso de la expresión. Al final del post te dejo el enlace de una web que te permite insertar una expresión para obtener el gráfico o construirlas tú mismo.
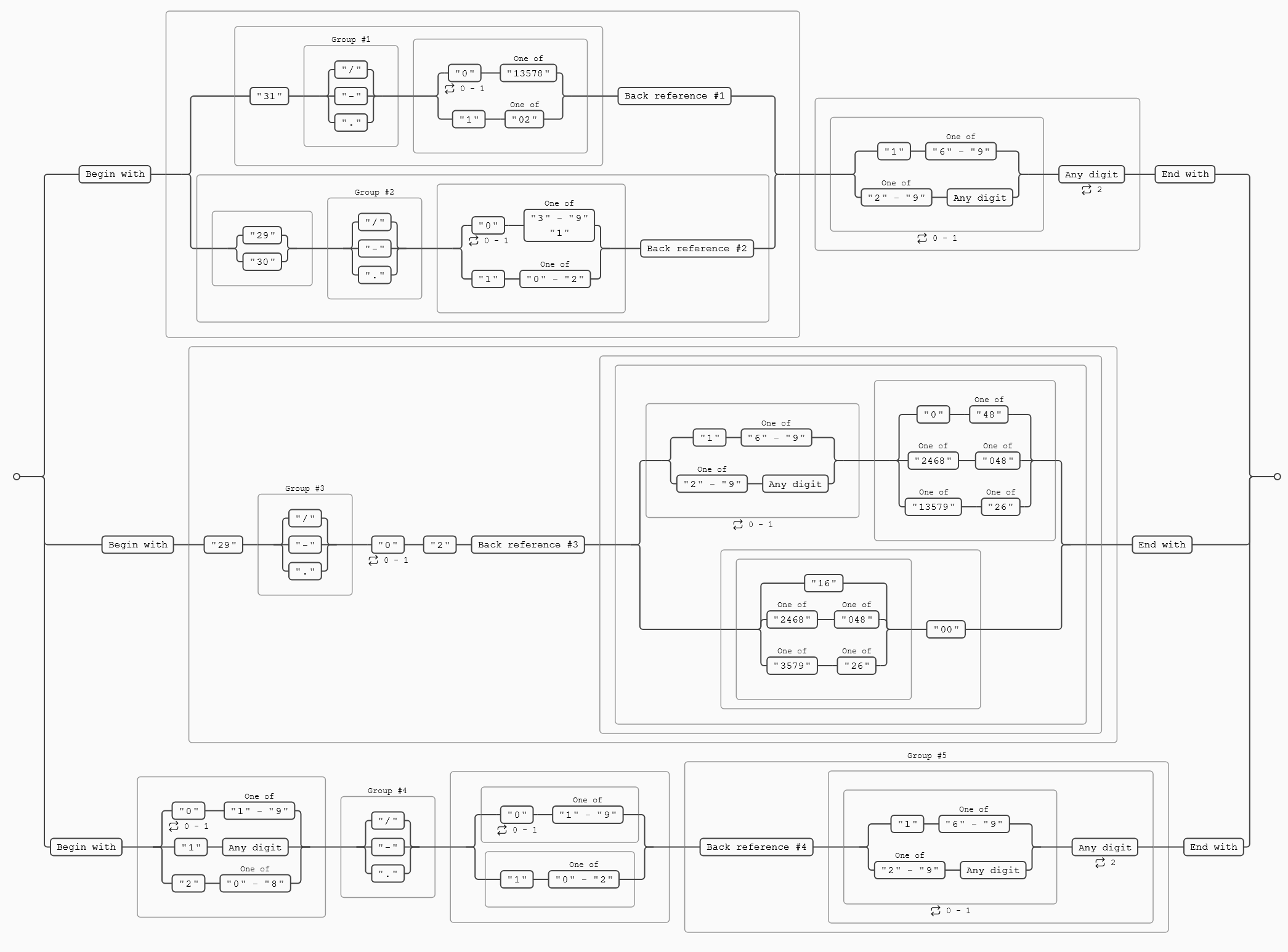
Explicación de la expresión regular:
Como vemos nada más empezar tenemos tres alternativas, vamos a analizar cada una de ellas por separado para entender cómo está funcionando esta expresión.
La rama superior empieza validando si el día es 31, en cuyo caso valida que el mes sea el 1,3,5,7,8,10 o,12 para validar el año a partir de 1600 hasta el 9999. Si el día empieza por 29 o 30, comprueba que el mes es 1 o está ente el 1 y los rangos 3 a 9 o 10 - 12, para finalmente validar el año de la misma manera de antes. Como puedes ver excluye al 2 en el mes, ya que febrero no puede tener 29 días salvo los años bisiestos, esto lo hace en la rama central.
La rama inferior hace la validación para los días que van del 1 al 28, en cuyo caso valida que el mes está entre dentro del rango 1-12, puesto que todos los meses tienen 28 días, y valida el año de la misma manera que la rama superior, siendo válidos los años de 1600 a 9999.
La rama media es la más interesante, se encarga de validar las fechas que empiezan en 29 y el mes es 2, para pasar a validar si el año es bisiesto o no:
- Valida los dos primeros dígitos si están entre 16 y 19 o entre 20 y 99, en este caso las terminaciones, los dos dígitos restantes, válidos son por grupos:
- 0 y [48]
- [2468] para el primer dígito y [048] para el segundo
- [13579] para el primer dígito y [26] para el segundo
- Valida los siguientes casos:
- 1600
- años que empiecen por [2468], seguidos de [048] y terminen en 00
- años que empiecen por [3579], seguidos de [26] y terminen en 00
Los casos anteriores se corresponden al cálculo del año bisiesto:
- Un año es bisiesto si es divisible por 4.
- Sin embargo, si el año es divisible por 100, no es bisiesto a menos que también sea divisible por 400.
Con esta expresión nos podemos hacer una idea de la gran complejidad y la potencia que pueden llegar a alcanzar este tipo de expresiones, lo importante puede ser construirlas paso a paso, probarlas y documentarlas y lo costoso que puede resultar mantenerlas. Como hemos dicho llegado cierto punto de complejidad, quizá sea interesante plantearse el uso de lenguajes de programación, si fuera posible.
Algunos ejemplos típicos
e-mail (versión simple)
\b[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}\b
e-mail (versión compleja)
/^(([^<>()\[\]\\.,;:\s@"]+(\.[^<>()\[\]\\.,;:\s@"]+)*)|(".+"))@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$/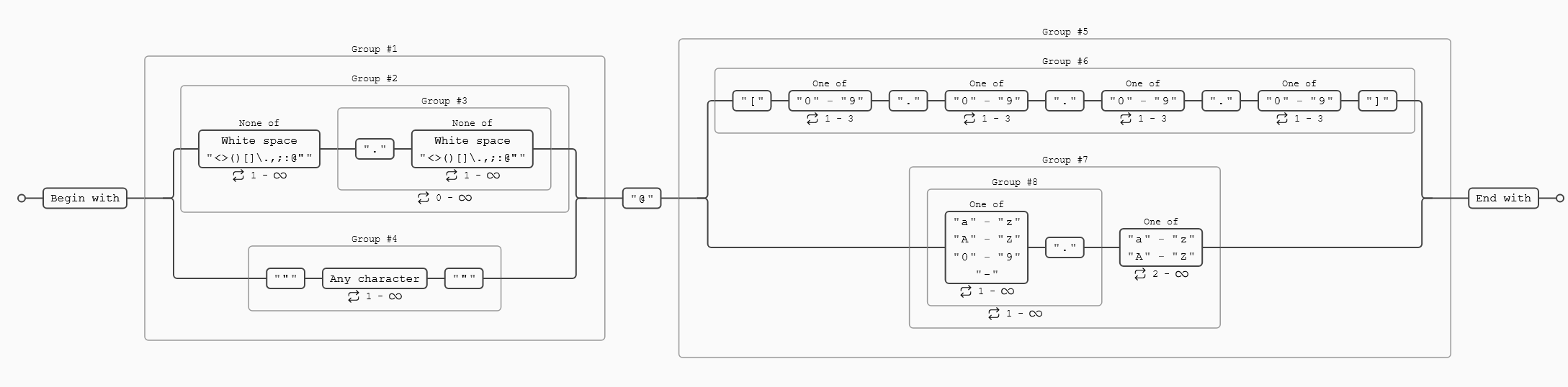
e-mail (RFC 5322 Official Standard)
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])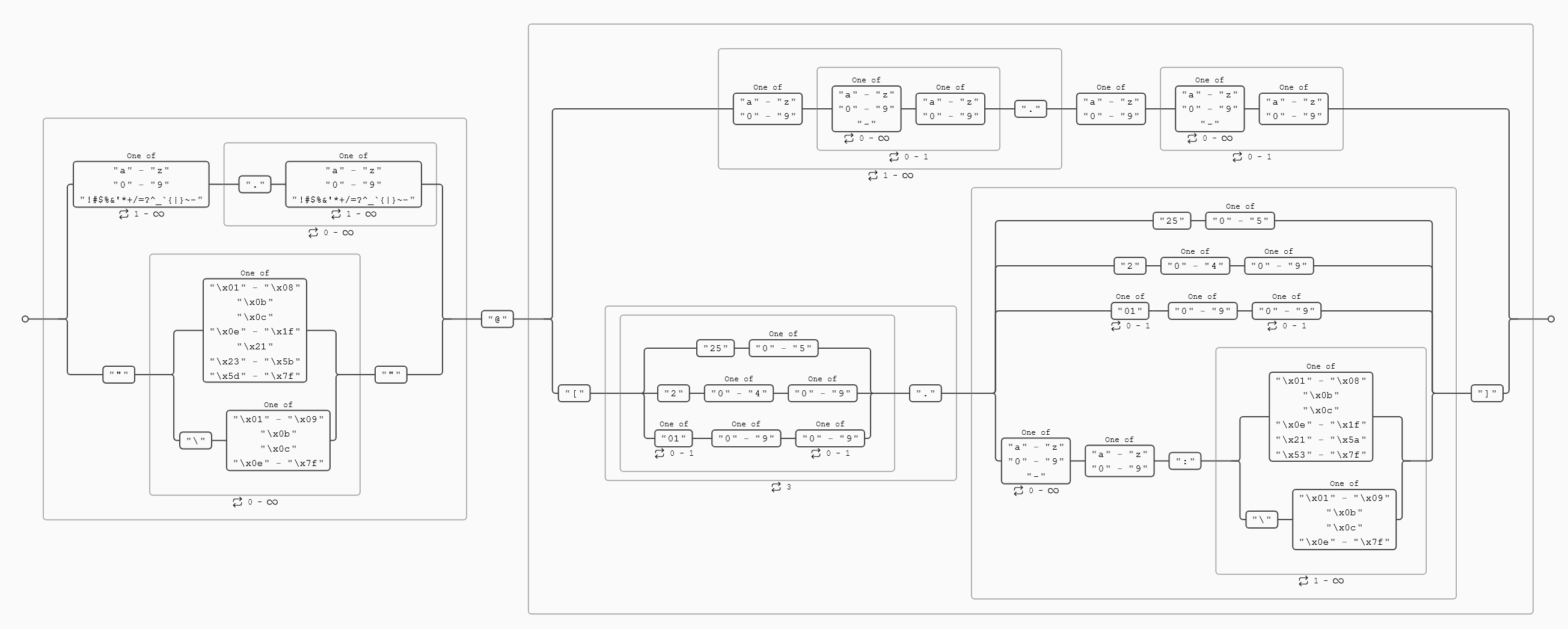
DNI
^[0-9]{8}[\s-]?[TRWAGMYFPDXBNJZSQVHLCKE]$
Contraseña de 8 dígitos con al menos una mayúscula, una minúscula y un carácter especial
^(?=.*[A-Z])(?=.*[a-z])(?=.*\d)(?=.*[!@#$%^&*()_+])[A-Za-z\d!@#$%^&*()_+]{8}$

Nombres de usuario (3 a 16 caracteres)
^[a-z0-9_-]{3,16}$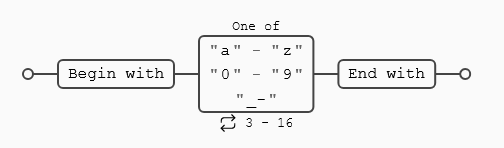
Valor hexadecimal
^#?([a-f0-9]{6}|[a-f0-9]{3})$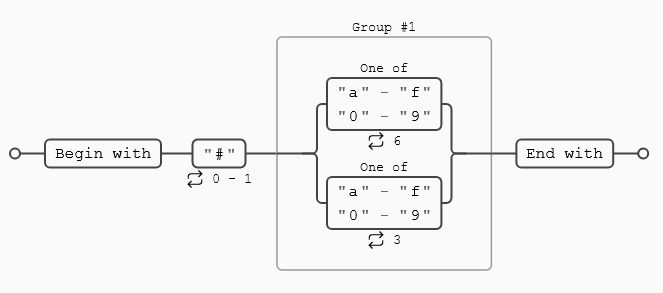
EAN13
^(?!.*(.).*\1)[0-9]{13}$

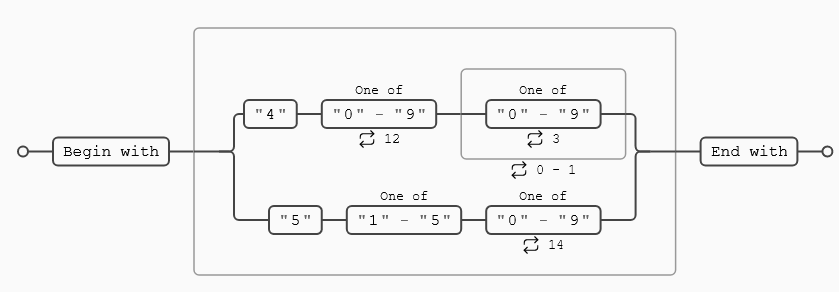
Tarjetas de crédito
^(?:4[0-9]{12}(?:[0-9]{3})?|5[1-5][0-9]{14})$
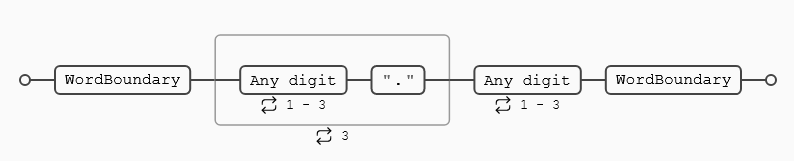
Fechas en formato ISO
\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}(?:\.\d+)?(?:Z|[+-]\d{2}:\d{2})

Direcciones IPv4
\b(?:\d{1,3}\.){3}\d{1,3}\b
URLs con protocolo
^(https?|ftp):\/\/[^\s/$.?#].[^\s]*$
Eliminar líneas en blanco de un documento
^\s*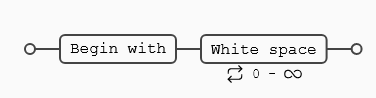
Líneas que terminan en "algo"
^(?=.*algo$).*$
Líneas que no terminan en "algo"
^(?!.*algo$).*$
Líneas de x caracteres o más:
^.{x,}$
Líneas de x caracteres o menos:
^.{1,x}$
Buscar palabras repetidas en un texto:
(\b\w+\b)(?=.*\b\1\b)
Conclusiones
Hasta aquí llega la entrada sobre conceptos menos básicos de las expresiones regulares incluyendo:
- Expresiones regulares ávidas y perezosas (
?). - Alternancia, que se cumpla una expresión o parte ella u otra (or).
- Condicionales, si se cumple un patrón que se cumpla una condición y en caso contrario que se cumpla otra (if).
- Aserciones para buscar un patrón si se cumple un patrón (o no), antes o después de la coincidencia, lookahead, lookbehind...
- Modificadores para cambiar el comportamiento por defecto de una expresión regular como (?i), (?g), (?s) o (?m).
- Consejos y un surtido grupo de ejemplos típicos.
- Construcción de una expresión paso a paso.
- Análisis de una expresión compleja.
Con estas herramientas serás capaz de construir expresiones regulares complejas, así como leer, espero que con espíritu crítico otras expresiones regulares, conociendo como funcionan y posibles alternativas. Si has llegado hasta aquí gracias, espero que todo lo que hemos visto te ayude a adentrarte en el mundo de las expresiones regulares, o te sirva de ayuda para ver algo que aún no conocías, o porqué no de referencia.
Referencias y recursos
Estupenda página para practicar expresiones regulares, cuenta con un resumen, un apartado para probar tus expresiones y varias opciones interesantes como la de explicar cada parte de la expresión regular:
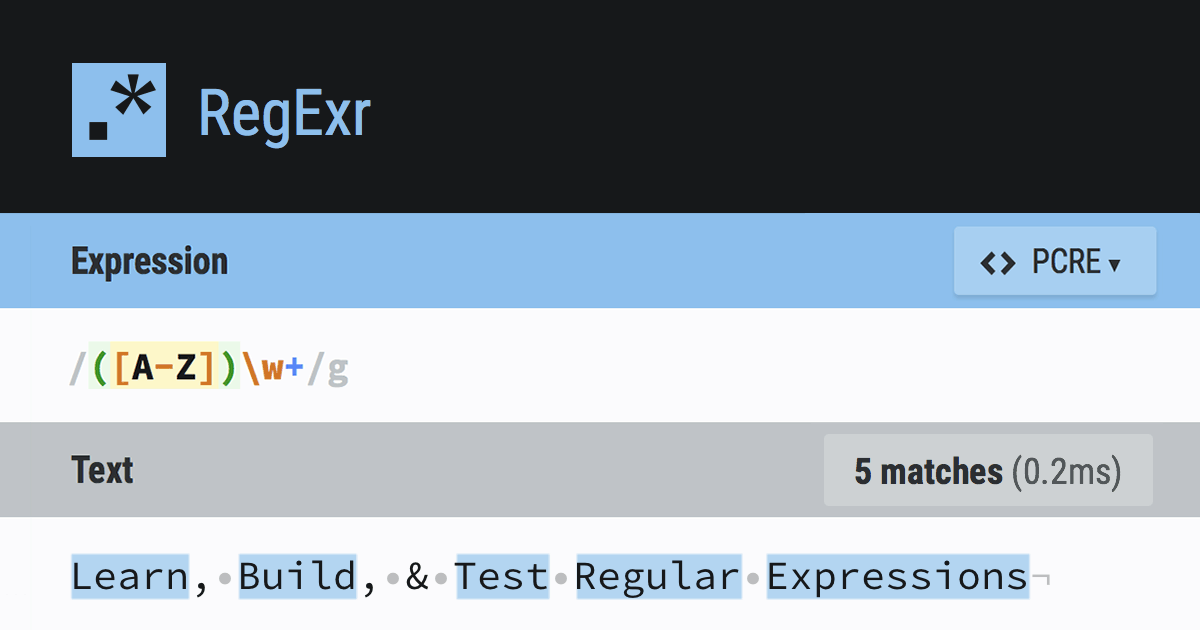
Página similar a la anterior, que también funciona muy bien:
Página con información muy completa sobre expresiones regulares:

Otra página interesante con información de expresiones regulares:

Interesante herramienta que te puede ayudar a construir expresiones regulares:
 Olaf Neumann
Olaf NeumannWeb que genera los esquemas explicativos de casi cualquier expresión regular y que hemos usado en esta entrada del blog:

Te dejo algunos juegos por si quieres aprender o practicar expresiones regulares de una manera diferente:
